Handbook
The Arrowhead fPVN Handbook on industrial semantics – Using IDO as upper ontology¶
Introduction¶
The Arrowhead flexible Production Value Network (fPVN) project is a European R&D initiative addressing the challenge of semantic interoperability across heterogeneous industrial data models and standards. Despite the availability of information model standards in industry since the mid-1990s, seamless interoperability has not been achieved — largely due to diverging model architectures, different modeling languages, and standardization groups prioritizing the success of their own standards over broader business needs.
Arrowhead fPVN proposes a fundamentally different approach based on W3C standards and semantic technologies: all engineering standards are transformed into a shared semantic framework using OWL 2 DL, SKOS, SPARQL, and SHACL, and aligned to a common upper ontology — the Industrial Data Ontology (IDO, ISO 23726-3). Rather than creating a single fully integrated data model, the approach uses multiple knowledge graphs, each representing a standard or domain, connected through semantic alignment. This enables scalable interoperability that improves incrementally as more alignments are added.
Work Package 3 (WP3) of the project is responsible for defining and selecting data model languages and providing guidelines and tools for the use cases. Its work spans three deliverables: D3.1 (survey of major industrial data models), D3.2 (semantic web extension and IDO alignment), and D3.3 (proposals for updating major industrial data model standards). The standards directly validated through the project’s use cases include ISO 23726 (IDO), ISO 10303 (STEP), ISO 15926, DEXPI, CFIHOS, and SysML v2. The project has been a named supporting project of the ISO 23726 standardization effort since 2022, and collaborates closely with the DISC (Digitalization and Information Standards Subcommittee of IOGP) and the CFIHOS Semantics working group.
How to read this document¶
This Handbook is one of four companion artifacts produced by the Arrowhead fPVN working group to document the resulting framework for industrial semantics using IDO as upper ontology (Table 1).
| Artifact | Purpose |
|---|---|
Handbook |
Full rationale, methodology, competency question framework, ontology architecture, and pattern library overview. Read this to understand why the framework is structured as it is and how to use it. |
Patterns |
Normative, per-pattern specifications. Each document is self-contained and cross-references the Handbook for methodology context. |
Use Cases |
Worked examples demonstrating the framework applied to real industrial datasets (pump lifecycle, power transformer, CFIHOS data handover). Illustrative, not normative. |
Guidelines |
Condensed entry-level summary. The recommended starting point for practitioners who need a quick-start reference. |
Suggested reading paths:
-
New to the framework? → Start with the Guidelines, then return here for Motivation and Methodology.
-
Implementing a pattern? → Read Methodology and Ontology architecture, then go directly to the relevant Patterns.
-
Contributing a use case? → Read Competency questions and the nearest existing Use Case document.
Note
Some terminology used in this document --- in particular the distinction between intrinsic and assigned properties (Intrinsic and assigned properties) --- has not yet been formally reviewed by the IDO core team and may require alignment with future IDO releases. Pending decisions of this kind are collected in Open issues and pending decisions.
Fragmentation despite decades of standardization¶
Cross-disciplinary data exchange is still often document-centric due to historical reasons. The consistent modeling of properties — such as dimensions, material, pressure, or temperature — is a fundamental prerequisite for achieving seamless digital integration of engineering, operations, and regulatory processes. Within individual disciplines, standards for structured data exchange already exist. Through initiatives such as the IDTA with the Asset Administration Shell, steps toward semantic interoperability are already being taken. However, the following remains unaddressed: Properties like voltage, pressure, material grade or vector group are captured in each phase and system, often with different units, data types, and naming conventions. As a result:
-
Engineers maintain the same attribute in separate tools with divergent formats.
-
Domain to domain handovers introduce semantic ambiguity and interpretation errors.
-
Data conversion and manual mapping efforts delay decisions and inflate costs.
Modern engineering and operations rely on characteristics — such as pressure, voltage, power rating, material, or orientation — that are used and exchanged throughout the lifecycle of industrial assets. Yet despite decades of standardization, the way these characteristics are defined, packaged, and interpreted varies widely between disciplines, tools, and standards.
In practice:
-
Data remains siloed in discipline-specific models, schemas, and spreadsheets.
-
Manual mapping is needed even between standards claiming to support interoperability.
-
Redundant and ambiguous definitions of the same concept are frequent.
-
Data quality, traceability, and validation remain inconsistent across systems.
Today, cross-disciplinary data exchange still depends largely on document-based workflows. Within specific domains, structured data exchange standards do exist, but their scope is often confined to narrow lifecycle phases or technical disciplines.
This fragmentation not only hinders automation and consistency but also undermines digital twin strategies, regulatory traceability, and efficient collaboration across supply chains. This is especially the case in engineering projects in industries such as energy, process, aviation, and construction, which involve multiple disciplines, tools, and data exchanges.
Existing initiatives and their limitations¶
Over the years, many international initiatives have tackled the challenge of structuring and exchanging product, engineering, or asset data. Each of them contributes valuable building blocks:
-
The Asset Administration Shell (AAS) defines a modular digital representation for industrial assets and properties.
-
ECLASS, IEC 61360, and ETIM offer classification and property definitions across product domains.
-
DEXPI enables standardized P&ID data exchange for the process industry.
-
CFIHOS provides a data model for information handover in capital projects.
-
ISO 10303 (STEP) defines structured representations of product data across the lifecycle.
-
QUDT and UCUM provide machine-readable definitions for units and quantities.
-
Initiatives like READI and bSI (IFC) work toward semantic interoperability in process and building domains.
-
The new ISO 23726-3 Industrial Data Ontology (IDO) offers a modular upper ontology for engineering concepts.
However, each of these initiatives addresses only a subset of the following dimensions:
-
Disciplines
-
Lifecycle phases
-
Data aspects (unit, value, governance, constraints…)
-
Toolchain coverage (design, engineering, operations)
-
Integration and mapping rules
-
Validation and formal semantics
Even the most comprehensive efforts — such as AAS or READI — either lack formal modeling patterns for properties, do not support lifecycle-specific value governance, or cannot represent semantic mappings across standards at the required granularity.
In this context, a framework is considered holistic if it covers all modeling aspects required to describe properties in a precise, interoperable, and lifecycle-compatible way; supports automated validation and reasoning; and remains neutral with respect to technology, lifecycle phase, and industrial sector.
Toward an integrated property modeling framework¶
At the core of this framework lies a dependency-based model of property components, clarifying how essential elements such as Property, Value, Unit, Quantity Kind, and Carrier Object interrelate. This model forms the semantic backbone for the harmonization activities presented in later sections. Rather than introducing a new standard or ontology, this work proposes a harmonization framework that connects and extends existing initiatives. The goal is not to replace, but to align and structure.
We define a framework as holistic if it:
-
Covers characteristics across domains and standards.
-
Supports full lifecycle semantics and governance.
-
Enables interoperability by design through reusable modeling patterns.
-
Is grounded in formal validation and machine-processable mappings.
-
Can grow incrementally, while preserving compatibility with existing systems.
To support systematic harmonization, this framework adopts the Industrial Data Ontology (IDO) as a semantic backbone. Complementary resources — including ISO data models, the PLM Reference Data Library (RDL), QUDT, UCUM, and IEC 61360 — are referenced to ensure compatibility with widely accepted representations of units, quantities, classifications, and domain-specific attribute structures.
The framework provides a structured integration layer rather than introducing a new standalone standard. Its objective is to align existing data sources, standards, and initiatives through a unified modeling approach. Key elements include:
-
A set of 13 Harmonization Aspects, each formalized as Competency Questions (CQs) to guide consistent information modeling.
-
A library of reusable Modeling Patterns, tailored to each aspect and use cases.
-
A pattern engineering process that delivers governance artifacts, validation tooling, and meta-model.
-
Concrete pilot mappings for ISO 10303, DEXPI, and CFIHOS to demonstrate applicability across diverse industrial domains.
The framework also establishes terminological clarity by explicitly differentiating between core components such as Property, Value, Unit, Quantity Kind, Scale, and Code System — providing a precise, reusable foundation for semantic interoperability. Harmonization across standards is achieved as a natural outcome of applying the Property Description Model and reusable patterns, rather than being treated as a separate objective.
This work does not offer a competing standard, but serves as a shared modeling backbone — one that enables standards, initiatives, and tools to become interoperable, complete, and traceable across domains and over the full asset lifecycle.
This framework does not prescribe any specific tools or implementation technologies. It focuses exclusively on property modeling and avoids defining general structural or functional relationships (e.g., part-of, feeds). These are left to the hosting data models.
A central Pattern Library is required to ensure consistent, reusable, and unambiguous property descriptions. It reduces redundancies, aligns terminology across domains, and supports harmonization with international standards. This library acts as the methodological backbone for capturing and managing properties in a way that is both human-readable and machine-interpretable.
Figure 1 gives an overview of the definitions documented in this guideline.
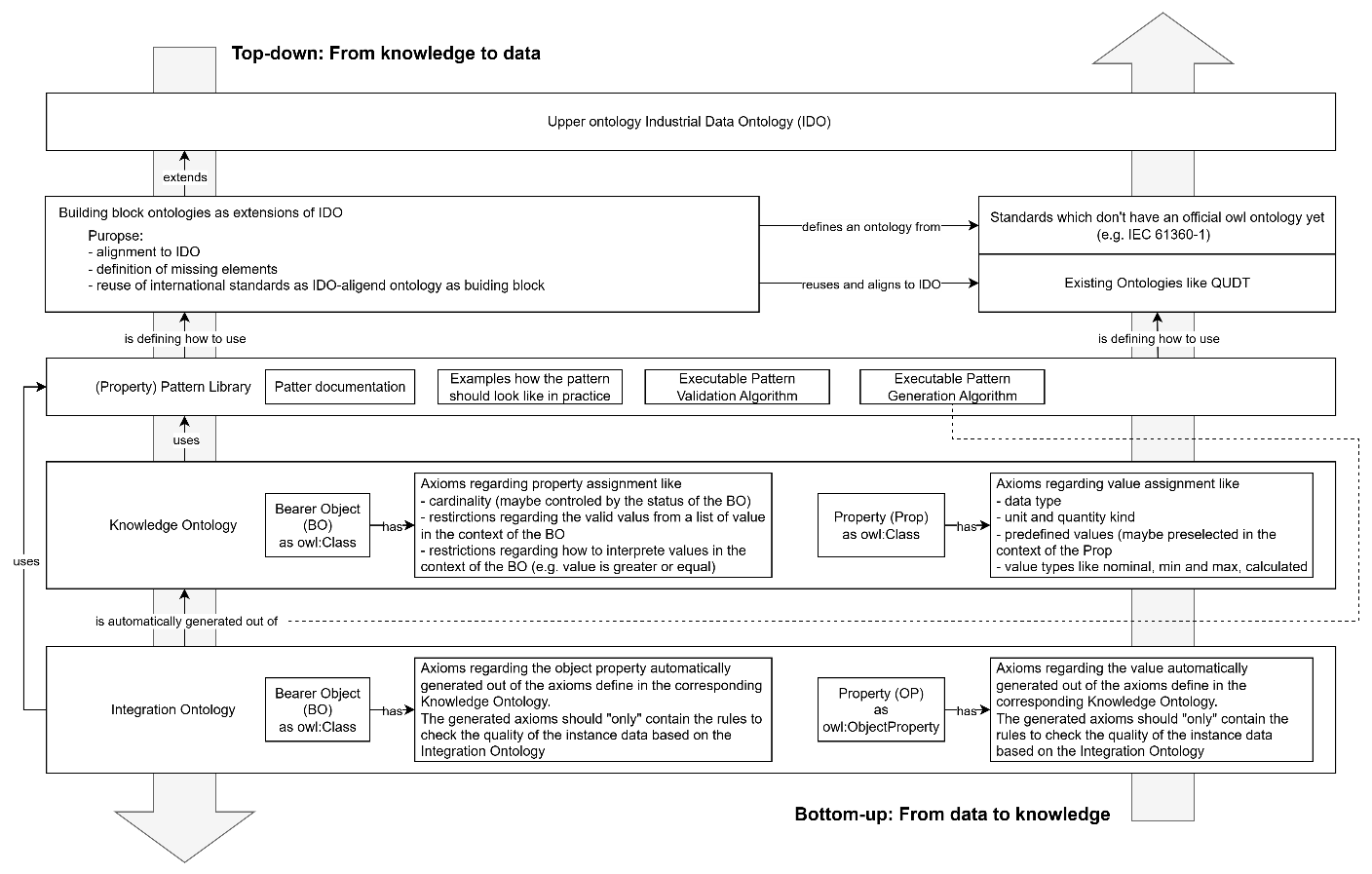
Two approaches are mentioned in the picture:
-
Top-down: From knowledge to data and
-
Bottom-up: From data to knowledge
The focus of this guideline is on the top-down approach.
Project scope and requirements¶
The guidelines in this document are comprehensively formulated and go beyond the scope of the Arrowhead fPVN project. The requirements listed in this preliminary section show what should be focused on as deliverable for the Arrowhead fPVN project in consideration of this guideline.
The requirements are:
-
Data Storage: Data must be stored in semantic web triple stores (or quad stores). While data sources can originate from relational formats, such as SQL databases, JSON files, or spreadsheets/CSV files, the semantic web format is preferred to ensure full accessibility for both humans and (AI) agents.
-
Data Exchange Structure: Data exchange structures should be simple and consistent. Simplicity does not imply minimalism; the structure for a single property may be complex, but the same format should be used universally.
-
Handling Extensive Property Sets: Exchanged data will typically include thousands of properties, which introduces specific requirements:
-
Component-Specific Properties: Physical properties must be associated with the specific component or part of the equipment they describe. Each equipment class should provide a corresponding object model to support this.
-
Structured Property Naming: Property names, whether quantifiable or descriptive, should follow a structured naming convention. This structure should incorporate aspect names derived from an ontology. This ensures that new property names can be created in a standardized way or matched in discovery to existing names if they are synonyms.
-
Property Grouping: Property groups help organize properties into clear workflow items. While property groups naturally align with equipment data sheets, they are essential to every other type of data set too, due to the large number of properties associated with items and their components. Even in cases with fewer properties, the standard grouping structure should still be maintained for consistency.
-
Metadata Support: Each property should be capable of holding metadata and in most cases, will require it.
Note
Similar requirements are valid for classes. This guideline has the focus on Property modeling. Therefore, requirements for classes are out of scope in this guideline.
Motivation¶
The motivating scenarios in Motivating scenarios illustrate the concrete industrial situations this framework addresses — from early requirement capture (UC-01 Early concept and requirement capture) and spec-to-product fit checks (UC-02 Spec-to-product fit check) through cross-standard handover (UC-06 DEXPI/CFIHOS/STEP alignment for handover) and operations (UC-08 Operations and condition monitoring) to decommissioning (UC-10 Decommissioning and records). Each scenario exposes a specific gap that the framework closes through explicit property definitions, lifecycle-aware modeling, and machine-readable validation. The following subsections explain what drives the need for this approach and what changes when it is applied.
From fragmentation to explicit, reusable properties¶
Today, properties are still too often defined and exchanged document-centrically and domain-locally: spreadsheets, PDFs, discipline-specific schemas, and implicit conventions. The consequences are familiar:
-
Redundancy & drift — the same property is redefined with different names, datatypes, or units.
-
Ambiguity — missing quantity kinds or scales lead to misinterpretation (e.g., "20" = 20 what?).
-
Hidden assumptions — lifecycle-phase specifics and dependencies remain tacit.
-
Fragile exchange — without machine-readable constraints, mappings become manual and error-prone.
The opportunity: define each property once, completely, and explicitly — so it can be reused across standards and tools, validated automatically, and governed transparently. Harmonization then follows as an outcome of consistent modeling.
What changes with this framework¶
The framework establishes a single source of truth for each property through reusable definitions that carrier objects reference rather than redefine, and keeps human-readable specifications synchronized with formal constraints so that narrative and machine-readable views travel together. A competency-question-driven workflow ensures that experts provide only the information relevant to their property type, eliminating gaps without overburdening contributors. Phase-specific values and constraints are modeled explicitly to embed lifecycle awareness into every property definition, while mappings and validation are treated as first-class artifacts so that interoperability is achieved by design rather than as an afterthought.
Motivating scenarios¶
The following scenarios cover ten representative industrial situations of the asset lifecycle — from early concept capture through operations to decommissioning. Each scenario identifies a concrete gap that arises without structured property modeling and shows how the framework closes it through explicit property definitions, lifecycle-aware value governance, and machine-readable validation. Together they illustrate the breadth of contexts in which the framework delivers value and serve as the reference cases for which the patterns and competency questions in this Handbook are validated.
UC-01 Early concept and requirement capture¶
Goal: Capture requirement properties (e.g., nominal voltage, design pressure) early, even before location/site is fixed.
How: Typology = Quality → CQs for quantity kind, units, permissible values, phase = Concept/Specification.
Success: A property package exists with clear definition, value constraints, and governance; later phases reference/extend it.
UC-02 Spec-to-product fit check¶
Goal: Ensure a product’s rated voltage satisfies a requirement’s nominal voltage by at least 10%.
How: Define both properties with quantity kind = voltage, units (e.g., V), and a dependency rule (rated ≥ 1.10 × nominal).
Success: Automated validation flags mismatches; lifecycle traceability preserved (requirement vs. product value).
UC-03 Alarms, setpoints, and measured values¶
Goal: Model high/low alarm limits and setpoints consistently with measured values.
How: Typology = Quality; unit + scale (e.g., °C is interval, dB logarithmic); measured values carry timestamps, uncertainty, reference conditions.
Success: Alarms evaluate correctly; data analytics can interpret values safely across systems.
UC-04 Reference property for role assignment¶
Goal: Assign Project Manager from existing Person instances.
How: Typology = Reference; CQs for target class (Person) and selection scope (e.g. HR-approved instances).
Success: No free-text drift; governance of the reference set is explicit.
UC-05 Classification and reference designation¶
Goal: Capture classification/reference designation as properties, not free text.
How: Typology = Identifying (codes) or Reference (selection from a controlled class list); value constraints via code systems.
Success: Consistent codes across BOM, P&ID, and asset register; easy cross-navigation.
UC-06 DEXPI/CFIHOS/STEP alignment for handover¶
Goal: Align properties in P&ID (DEXPI) and handover (CFIHOS) with product data (STEP)
How: Properties defined once via PDM; mappings recorded; for example, SHACL checks enforce constraints at handover.
Success: Fewer manual mappings; consistent semantics through lifecycle milestones.
UC-07 Supplier technical data sheets¶
Goal: Exchange technical data sheets (TDS) data with unambiguous property semantics.
How: Supplier adopts the property definitions (ID, definition, datatype, units, constraints); CQ bundle drives a form.
Success: Zero ambiguity on units, limits, and allowed values; automated ingestion possible.
UC-08 Operations and condition monitoring¶
Goal: Store and interpret measured values consistently across systems.
How: Properties carry unit, scale, timestamps, uncertainty, reference conditions; lifecycle phase = Operation.
Success: Analytics and alarms are portable; unit conversions safe; provenance intact.
UC-09 Change, versioning, and deprecation¶
Goal: Evolve properties without breaking consumers.
How: Governance metadata (owner, version, approval), deprecation markers, replacement links; migration notes in the spec.
Success: Consumers can upgrade safely; mappings remain traceable.
UC-10 Decommissioning and records¶
Goal: Preserve key property values and provenance for compliance.
How: Lifecycle phase = Decommissioning; capture final states and references (e.g., disposal records).
Success: Auditable trail; consistent semantics to the end of life.
Success criteria¶
The following criteria define how the effectiveness of the framework is measured across the motivating scenarios. They apply both at the level of individual property definitions and at the level of cross-standard interoperability.
-
Completeness: % of properties with full PDM coverage and CQ bundle.
-
Consistency: validation pass rate (e.g. SHACL) across repositories/exchanges.
-
Reuse: # of carrier classes referencing shared properties; reduction in duplicates.
-
Interoperability: # of successful mappings (e.g., DEXPI↔CFIHOS↔STEP) without manual fixes.
-
Governance: lead time from draft to approved; clarity of version/provenance.
Methodology¶
This section defines the methodological backbone of the Holistic Property Modeling Framework. Its purpose is to ensure that every property — regardless of its domain, lifecycle phase, or originating standard — can be described completely, unambiguously, and in a machine-readable form. It builds a bridge between: Motivation — which defines why property harmonization is needed and in which scenarios it delivers value, and Competency Questions — which lists what information must be captured for a property via Competency Questions (CQs) and provides the complete reference set of CQs.
The methodology described here answers the question: How can we guide property experts — many of whom have no background in ontologies — to capture their knowledge in a structured way that can later be implemented in formal models? The approach is based on two pillars:
-
A Dependency Model that explains the structural relationships between all relevant elements of a property definition.
-
A Property Typology that enables experts to start with an intuitive classification, from which a tailored set of CQs guides them toward a complete property description.
The following sections describe these two components in a logical order: first the Property Description Model as the structural backbone, then the Property Typology as the intuitive entry point into the modeling workflow.
Property description model¶
The Property Description Model defines the set of elements required to describe any property in a complete, unambiguous, and reusable way. It provides the structural backbone for capturing implicit expert knowledge explicitly — so that it is both human-readable for review and machine-readable for validation, mapping, and automation. The model is domain-agnostic and lifecycle-spanning, ensuring that property definitions can be reused and harmonized across industries, standards, and tools.
The model is organized into clearly defined elements, each addressing a specific aspect of a property’s definition, governance, or use. While some of these elements will vary depending on the property type (see Property typology), all follow the same decomposition logic: break complex or implicit concepts down into explicit, formally represented parts.
Core elements of the property description model¶
The core element of the property description model can be summarized as follows:
-
Identification & Naming
-
Unique identifier (persistent and stable across contexts)
-
Preferred name and synonyms
-
Language-specific labels
-
-
Definition & Semantics
-
Human-readable definition, written to avoid ambiguity
-
Source/reference of the definition (standard, specification, expert group)
-
Notes on intended use and scope
-
-
Value Structure
-
Data type (string, number, boolean, date, etc.)
-
Quantity kind (if applicable)
-
Unit of measure (if applicable, aligned with recognized unit systems)
-
Value constraints (e.g., permissible value set, value range, pattern)
-
Calculation or derivation rules (if value is computed from other properties)
-
-
Lifecycle & Context
-
Applicable lifecycle phases (design, manufacturing, operation, maintenance, decommissioning)
-
Domain or discipline relevance
-
-
Governance & Provenance
-
Owning organization or authority
-
Versioning and change history
-
Approval and review process
-
-
Dependencies & Relationships
-
Value dependencies — where the value of one property constrains another
-
Reference properties — where the property’s value is selected from a controlled set of instances belonging to another class (e.g., role assignments)
-
Calculation dependencies — where the value is derived from other properties according to formal rules
-
Note
Only Reference Properties are modeled as relations (e.g. Manufacturer); structural and functional relationships are out of scope of this guideline but part of other guidelines.
Why decomposition and explicit knowledge capture matter¶
The harmonized property modeling process aims to ensure that every property is described in a way that is complete, unambiguous, and in a form that is both human-readable and machine-readable. Achieving this requires more than simply listing attributes: it involves decomposing each property into its constituent elements, making implicit expert knowledge explicit, and documenting all relevant relationships to other concepts.
Decomposition as a foundation for clarity
Most properties, even seemingly simple ones, carry multiple layers of meaning. For example, a Rated Frequency property implicitly assumes a quantity kind (frequency), a set of permissible units (e.g., Hz), and — if constrained — an allowed value set (e.g., 0, 16 %, 50, 60 Hz). Without decomposition, such information often remains in the heads of experts or hidden in domain-specific documents, making it inaccessible to other stakeholders or systems.
Explicit knowledge capture for cross-domain interoperability
By systematically breaking a property down into well-defined elements — identifier, definition, data type, quantity kind, permissible values, lifecycle relevance, governance, and dependencies — ambiguities can be eliminated at the source. This enables different disciplines, tools, and standards to interoperate without costly manual reconciliation. The same structured approach ensures that knowledge provided by experts without ontology skills can still be transformed into formal, machine-processable representations.
Dependencies as a specific outcome of decomposition
One critical outcome of decomposition is the identification of dependencies between properties:
-
Value dependencies — where one property’s value constrains another.
-
Reference properties — selection from a controlled set of instances of another class.
-
Calculation or derivation rules — where one property is computed from others.
Without explicitly modeling such dependencies, critical context can be lost, leading to misinterpretation or inconsistent application. This is particularly visible during data exchange:
-
Units may be omitted or mismatched (e.g., bar vs. psi).
-
Enumeration codes may differ across standards without explicit mapping.
-
Lifecycle-phase-specific values may be incorrectly merged or overwritten.
Benefits for governance and automation
A fully decomposed and explicitly documented property can be (1) reviewed and validated by domain experts in a human-readable form; (2) processed by validation and reasoning tools for automated checks; (3) mapped reliably between different standards and data models; (4) governed through versioning, provenance tracking, and controlled evolution. In short, decomposition and explicit knowledge capture form the backbone of the harmonization process: they bridge the gap between informal domain expertise and formal, reusable, and interoperable property definitions.
Linking the property description model to user guidance¶
The Property Description Model is not just a theoretical construct — it directly drives the user guidance process that enables domain experts to create high-quality property definitions without needing ontology expertise.
Competency Questions as a navigation tool
Each element of the Property Description Model is linked to one or more Competency Questions (CQs) from Competency Questions. When an expert defines a property, the system can guide them step-by-step through the relevant CQs, ensuring that all required information is captured. For example:
-
Identification-related CQs ensure unique IDs and clear naming.
-
Value structure CQs capture data types, units, and permissible values.
-
Lifecycle context CQs link properties to relevant phases.
-
Relationship CQs capture dependencies and reference selections.
Adaptive guidance based on property type
The first step in user guidance is classifying the property using the property typology (Property typology). Depending on whether it is a quality property, an identifying property, a reference property, or a descriptive property, the system can adapt the sequence and scope of CQs:
-
A Quality Property will trigger unit/quantity kind CQs.
-
A Reference Property will trigger CQs about the reference target class and permissible instance sets.
-
An Identifying Property may skip unit-related CQs but focus on uniqueness and governance.
From human-readable input to machine-readable definitions
The answers given by experts are stored in a structured way that serves both purposes: Human-readable for review, discussion, and governance, and Machine-readable for validation, reasoning, and interoperability mappings. By connecting the Property Description Model to a CQ-driven guidance process, the framework ensures that properties are not only modeled consistently but also with complete, explicit knowledge — ready for both expert review and automated processing.
Property typology¶
While the Property Description Model describes the structural backbone, the Property Typology provides the entry point for describing any property within the Property Description Model. It is the first classification step in a guided process that enables domain experts — many of whom may have no background in ontologies — to capture their knowledge in a way that is both human-readable and machine-readable.
The goal is to ensure that each property can be completely and unambiguously described, and that implicit knowledge in the minds of experts becomes explicit, interpretable by humans and formally usable by machines. This typology does not replace detailed decomposition but sets the stage for it by narrowing the scope of subsequent questions and required metadata.
The classification of properties at this first step also establishes the entry point into the 13 Harmonization Aspects introduced in Competency Questions, ensuring that subsequent modeling decisions follow a consistent and reusable structure.
Core property types¶
The typology distinguishes between the following broad types of properties:
Quality Properties — Characteristics or parameters that can be:
-
Continuously measurable (e.g., Design Pressure, Length, Operating Temperature)
-
Captures measurable, enumerable (Example: Rated Frequency, unit: Hz; permissible values: 0, 16%, 50, 60 Hz), the distinction between continuous, discrete, and operational states can be deferred until later CQs clarify units, value sets, or lifecycle contexts.
-
Discretely enumerated (e.g., Material Grade, Protection Class)
-
Stateful or operational (including limits, setpoints, alarms, and measured values, e.g., High Alarm Limit (Temperature), Measured Voltage)
-
This also includes calculated or derived values, as well as operational thresholds and alarms, where applicable.
Identifying Properties — Unique identifiers or codes that distinguish one instance of an asset, object, or document from another (e.g., Serial Number, Asset Tag)
Classification Properties — Properties that assign the bearer object to a category, a standard or a classification system. They are used to establish semantic alignment between the bearer object and controlled vocabularies, coding systems, or taxonomies.
Example: RDS code according to IEC 81346 or standardized category identifiers from controlled classification schemes.
In some cases, a bearer object may require multiple classification properties to represent different perspectives, such as functional, structural, and organizational categorization. These scenarios must be supported without introducing inconsistencies.
Reference Properties — Properties whose value is chosen from a controlled set of instances belonging to another class (e.g., Project Manager selected from Employee instances).
This includes role assignments and selection-based relations; structural or functional relationships are not modeled as properties here.
Example: "Project Manager" (value selected from the class "Person" and the assignment of the property to the bearer object "Project"), "Supplier" (value from Organization instances).
Descriptive/Textual Properties — Free-text or descriptive attributes that cannot be reliably captured as enumerations, quantities, or references but are still essential for completeness (e.g., Maintenance Instructions, Special Notes).
Captures unstructured human-readable information relevant to the property but not suitable for measurement or enumeration.
Example: Installation Notes, Special Handling Instructions.
Why typology comes first¶
Starting with a property type classification serves two purposes:
-
Guidance Optimization — By identifying the property type upfront, the guidance process can adapt the Competency Questions (CQs) and required fields, reducing complexity for the expert and avoiding irrelevant prompts.
-
Clarity of Intent — This step ensures that the modeling process immediately captures the nature of the property before diving into detailed decomposition.
For example:
-
A Quality Property will prompt for unit, quantity kind, and permissible values
-
A Reference Property will prompt for the target class and permissible instances
-
An Identifying Property will focus on uniqueness, governance, and lifecycle applicability
The typology also determines which CQ pathways are presented to the expert during the guidance process, ensuring consistency and avoiding premature technical decisions.
The selection of property types also determines which sets of Competency Questions are presented in the modeling tool, thereby automating guidance for experts and ensuring consistent property descriptions across domains.
Link to the property description model¶
The Property Typology is Step 1 of the broader Property Description Model described in Property description model.
Once the type is identified, the process moves into structured decomposition, where each property is broken down into its constituent elements (identifier, definition, quantity kind, unit, permissible values, lifecycle relevance, dependencies, governance, etc.). For certain property types, governance attributes must also be captured, including version control, source of definition, approval status, and lifecycle ownership. These attributes ensure that properties can be maintained consistently and reused across organizational and system boundaries.
By combining a clear first-step classification, followed by systematic decomposition and CQ-based guidance, the framework ensures that every property is modeled consistently, completely, and ready for expert review as well as automated processing.
Intrinsic and assigned properties¶
Properties differ not only in what they describe but in how their values arise. This distinction has direct consequences for how they are modeled in IDO-aligned ontologies.
Intrinsic (quality) properties¶
An intrinsic property is one whose value is determined by the physical nature of the bearer object. The property cannot exist independently of the bearer, and its value is a fact about the object’s inherent state. Examples: operating pressure, mass, tensile strength, material composition, temperature. In IDO terms, intrinsic properties are modeled as lis:Dependent entities — specifically lis:Quality for measurable physical quantities. The value of an intrinsic property is an attribute of the bearer’s being: it is not assigned by any person or organization but is simply there as a consequence of what the object is.
Assigned properties¶
An assigned property is one whose value is externally attached to an object by human decision, convention, or administrative act. The object exists independently of the assignment; the assignment could change or be revoked without altering the object’s physical nature. Examples: tag number, manufacturer name, classification code, document reference, project manager, procurement category. Assigned properties are dependent on the bearer in the weak sense that they presuppose the bearer’s existence — but their value is a social or administrative fact, not a physical one. In IDO terms, these correspond to lis:Designation or a project-defined extension class within the lis:InformationObject branch.
The modeling debate and the project’s position¶
IDO’s top-level category structure — illustrated in Figure 2 and Figure 3 — forms the backdrop for an ongoing debate about where assigned properties fit within the ontology.

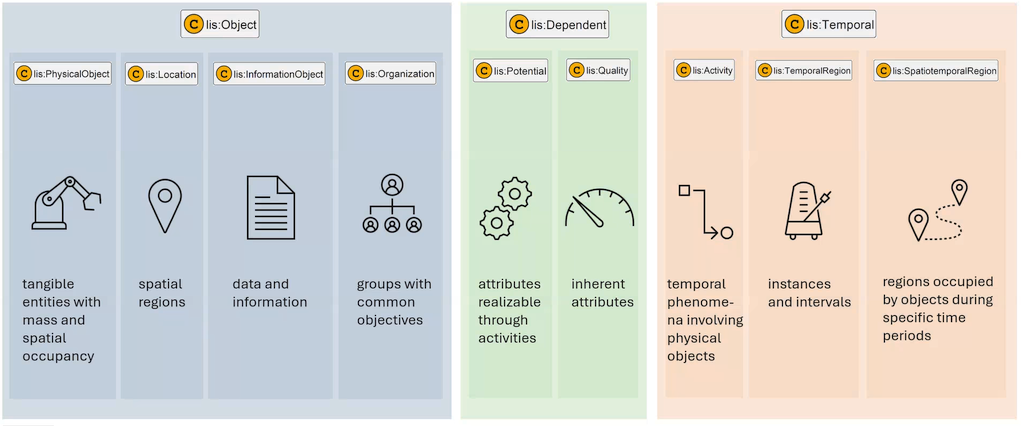
IDO’s upper ontology was originally designed with a strong focus on quality-like, inherent properties. IDO v4.2 (FDIS) defines lis:Dependent as "an entity that is an inherent quality or realizable potential of an object" — with the explicit emphasis on the word inherent. This raises a direct question for large-scale industrial data sets: should assigned properties be modeled as lis:Dependent entities, or do they require a distinct branch?
This question was raised explicitly by Onno Paap (December 2025) in the context of CFIHOS Semantics, which encompasses more than 10,000 properties: "Determining which of the more than 10,000 properties are intrinsic or not will cost us many work hours to identify, verify, and approve, with no apparent business benefit." The IDO core team confirmed that lis:Dependent covers inherent properties; assigned properties fall outside its intended scope.
This project takes the position that both branches are semantically necessary and should be modeled explicitly: Forcing assigned properties into the lis:Dependent branch creates a category error and produces misleading instance data. Keeping both branches explicit improves clarity for domain experts, supports correct automated validation, and makes the distinction queryable at the triple level. The distinction does not require any change to IDO core. It can be implemented at pattern level using subclasses and annotation conventions within the boundaries of the current standard.
Practical guidance¶
Use the Property Typology (Property typology) as the decision entry point:
-
Quality property → intrinsic branch (
lis:Quality→lis:QualityDatum) -
Identifying or Reference property → assigned branch (
lis:Designationor object property reification) -
Descriptive property → context-dependent; assess whether the value is determined by the bearer’s physical nature or by human annotation
Where this project’s position may require a future extension to IDO core, this is documented as a proposal to the IDO core team (Open issues and pending decisions, OI-01). Property aspects that qualify properties within each branch are described in Property aspects.
Property aspects¶
A property aspect is a qualifier that specializes a generic property within a given context, without creating a distinct property class. Aspects attach contextual meaning to property instances — specifically to the QualityDatum individual — rather than redefining the property class itself (Table 2).
| Property name | Aspect(s) | Meaning |
|---|---|---|
upper limit design pressure |
Range = upper limit, |
Maximum pressure assumed in structural design |
normal operating pressure |
Scope = normal, |
Typical value during sustained normal operation |
maximum allowable working pressure |
Range = maximum, |
Upper safety limit; structural constraint |
In each case, pressure is the reusable base property class. The aspects are applied as classifications to the QualityDatum individual, not to the property class.
Why aspects matter¶
Without aspects, the only alternatives are:
-
Proliferation: Define separate property classes for every contextual variant (
DesignPressure,NormalOperatingPressure,MaxAllowablePressure, …), leading to hundreds of near-identical definitions with redundant semantics and no machine-readable relationship between them. -
Loss of precision: Store all pressure variants under one property with no contextual differentiation, making automated validation and cross-system alignment impossible.
Aspects provide a third path: reuse the base property class and qualify individual values with explicit context. For large property sets — CFIHOS alone covers more than 1,300 properties today, with over 11,000 planned from JIP33 equipment data sheets — this reduction in class proliferation is essential for maintainability.
Aspect taxonomy¶
The following four aspect categories (Table 3) are recognized in this framework, derived from working group contributions (Onno Paap, Heiner Temmen) and aligned with IEC 62569-1. The specific class names used for value-side aspects (e.g., NominalDatum, NormalDatum, CalculatedDatum, UpperLimit, LowerLimit) and property-side aspects (e.g., DesignQuality, CalculatedQuality, ProvenanceQuality, ScopeQuality) originate from the PCA PLM Ontology (see The PCA PLM Ontology and property aspect vocabulary). Those classes have been updated to IDO v4.2 and reorganized into separate Value Aspect and Property Aspect ontology modules as part of this project’s work.
| Aspect category | Definition | Examples |
|---|---|---|
| Range | Direction or limit of the value | average, lower limit, maximum, minimum, nominal, normal, upper limit, tan tan |
| Scope | Operating regime, condition, or context | access, allowable, alternate, ambient, design, effective, emergency, equivalent, limits, normal, operating, rated, relative, rotational, thermal, total, vacuum, working |
| Origin | How the value was determined | actual, average, calculated, design, estimated, measured, rated, required, specified |
| Place | Spatial location or reference point | cross sectional, external, inside, internal, outside, surface, wall |
Note
A property name may embed a Bearer --- a sub-object or component to which the property applies (e.g., \"discharge normal working pressure\": discharge is a nozzle, not an aspect category). Bearers should be resolved by associating the property with the bearer object instance rather than encoding the bearer name in the property label.
Aspects can be combined. "Maximum allowable working pressure at the inlet" combines Range (upper limit), Scope (allowable), and Place (inlet).
IDO-compliant modeling of aspects¶
In IDO-aligned ontologies, the lis:hasQuality relation links a bearer object to a lis:Quality individual, which is then quantified via lis:qualityQuantifiedAs to a lis:QualityDatum. Aspects are modeled as OWL class restrictions applied to the QualityDatum — that is, as additional rdf:type assertions on the datum individual.
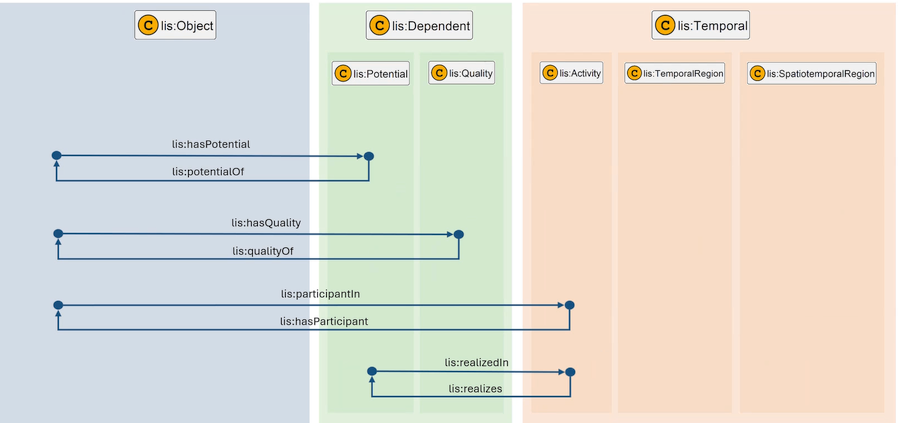
Figure 4 shows how the lis:hasQuality relation bridges lis:Object and lis:Dependent. The QualityDatum sits within the Object hierarchy as a lis:InformationObject, carrying the numeric value and unit while the Quality individual in the Dependent hierarchy carries the class-level meaning and the aspect classifications.
This approach:
-
Preserves IDO’s core reification structure with no changes to IDO core.
-
Avoids subclassing the base property class for every aspect combination.
-
Enables SHACL validation of aspect consistency (e.g., checking that every
DesignPressuredatum has exactly one Range or Scope aspect). -
Keeps aspects queryable: SPARQL can efficiently retrieve all "design" pressure values across all equipment instances.
TemporalDatum: IDO v4.2 extension for activity-contextualized aspects¶
When an aspect refers to a specific activity or time period — for example, "maximum pressure during commissioning" or "operating time during last maintenance cycle" — the standard QualityDatum pattern is insufficient, because durations and activity-scoped quantities are not physical quantities in the same sense as pressure or temperature. IDO v4.2 (FDIS, April 2026) introduces lis:TemporalDatum to handle this case. The canonical pattern is:
Activity —hasTemporalRegion--> TemporalRegion
|
temporalRegionQuantifiedAs
|
TemporalDatum —temporalValue--> xsd:duration
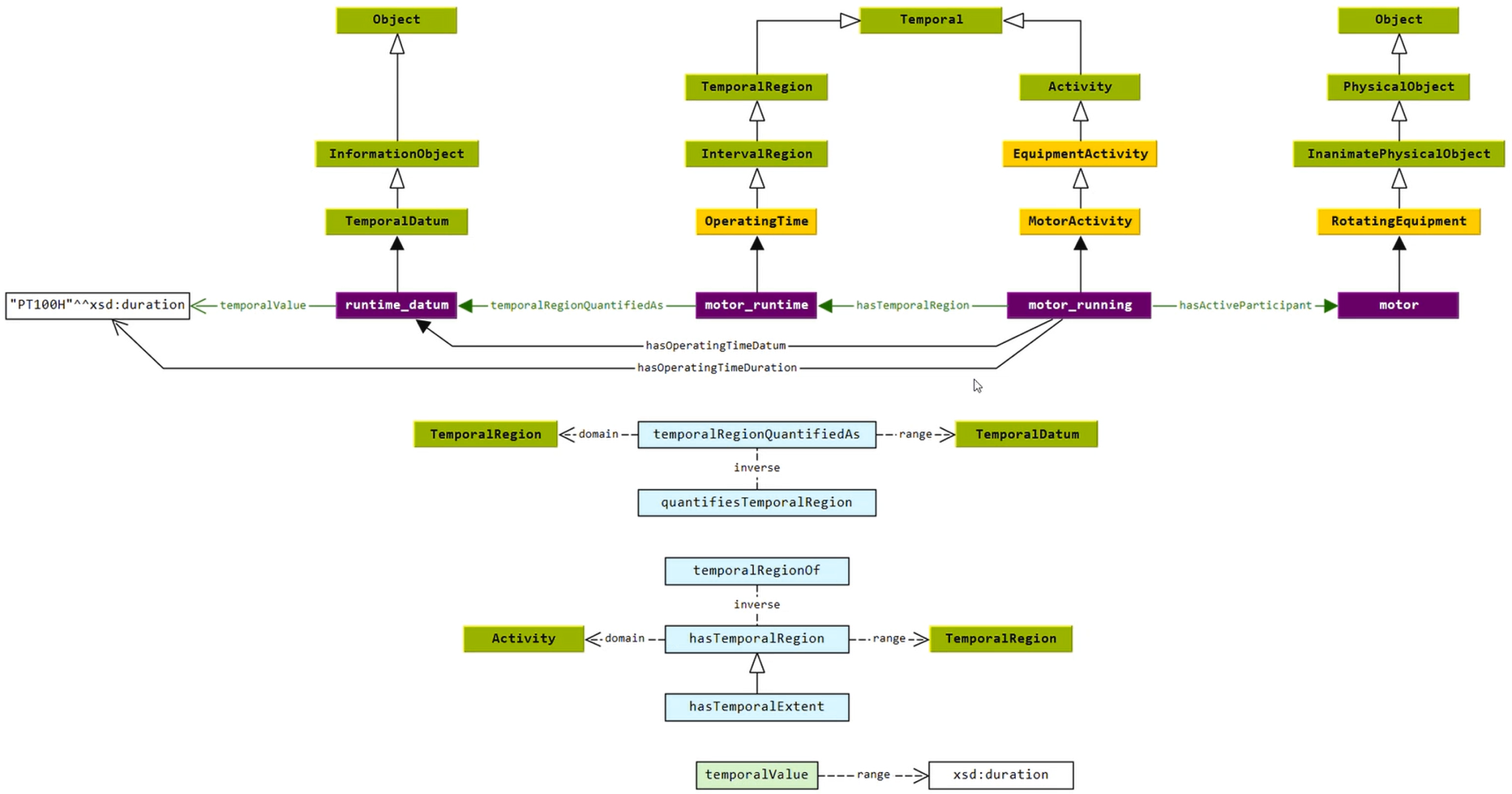
Figure 5 shows the complete pattern applied to motor runtime (motor_running → motor_runtime → runtime_datum → "PT100H"^^xsd:duration). The shortcut properties hasOperatingTimeDatum and hasOperatingTimeDuration shown in the diagram are not part of IDO core; they are domain-level shortcuts that should be defined per application and must be documented with a reference to the full canonical pattern.
This TemporalDatum mechanism is the recommended approach when the Origin or Scope aspect of a property references a specific activity or temporal context rather than a static operating condition.
Note
The formal OWL patterns, Turtle examples, and SHACL shapes for all aspect categories are defined in Property Classes Pattern.
Guided workflow¶
The harmonized property modeling process is designed as a guided workflow, ensuring that domain experts can create complete, unambiguous, and interoperable property descriptions without requiring ontology expertise. This workflow connects the Property Typology (Property typology) with the Property Description Model (Property description model) through a sequence of Competency Questions (CQs) from Competency Questions. The workflow proceeds in four main stages, described in the subsequent sections.
Step 1 — Initial typology classification¶
The process begins with the expert identifying the property’s top-level type according to the typology in Property typology. This decision serves as an early filter for subsequent CQs; reduces complexity by avoiding irrelevant questions; and ensures that the guidance process reflects the expert’s mental model. For example, if an expert selects Reference Property, the workflow will bypass unit-related CQs and instead focus on the bearer object and permissible instances.
Step 2 — Adaptive CQ navigation¶
Based on the initial classification, the system presents a tailored subset of CQs:
-
Quality Properties → CQs about quantity kind, units, permissible values, operational conditions, and lifecycle relevance.
-
Identifying Properties → CQs on uniqueness, governance, lifecycle applicability, and format constraints.
-
Reference Properties → CQs on bearer object, permissible instances, and governance of the reference set (structural/functional relationships remain excluded here).
-
Descriptive Properties → CQs ensuring clarity, scope, applicability, and lifecycle relevance of the description.
The CQ order is adaptive: answers given early can trigger or skip later questions. For instance, specifying a unit may trigger follow-up CQs on permissible values, while leaving the unit undefined may skip those steps until more context is provided.
Step 3 — Structured decomposition¶
The answers to CQs progressively fill the Property Description Model (Property description model), covering:
-
Identification & Naming (persistent ID, preferred label, synonyms)
-
Definition & Semantics (human-readable definition, intended scope, source)
-
Value Structure (data type; quantity kind & unit if applicable; value constraints: enumeration/range/pattern; calculation/derivation if any)
-
Lifecycle & Context (phase applicability; domain/discipline)
-
Dependencies & Relationships (value dependencies; reference properties; calculation dependencies)
-
Governance & Provenance (owner; version; approval; change log)
This decomposition ensures that implicit expert knowledge becomes explicit, and that all required metadata is both human-readable (for review) and machine-readable (for automated validation and mapping).
Step 4 — Review and consistency checks¶
Before a property is finalized:
-
Human-readable review: The expert reviews the human-readable description for clarity, correctness and accuracy.
-
Automated validation: Automated checks validate the machine-readable representation for constraints (e.g., unit/quantity kind consistency, value domain conformance, reference-set integrity, lifecycle constraints).
-
Issue loop: Any issues are fed back into the workflow for resolution.
This loop ensures completeness, internal consistency, and readiness for harmonization across standards and systems.
Step 5 — Publication, reuse and traceability¶
Once validated, the property is published with a stable identifier, version, and status; traceability hooks (provenance, CQ answer bundle, mappings) are stored; and the property becomes reusable across classes and projects; carrier objects reference (not redefine) it.
Definition of Done for a property¶
A property is done when:
-
All required elements of the Property Description Model are present and consistent,
-
Applicable CQs are answered (per the typology-driven pathway),
-
Validation passes (SHACL/Schematron or equivalent), and
-
Governance is complete (owner, version, status, provenance).
Why guidance matters¶
Without structured guidance, property descriptions risk being incomplete, inconsistent, or ambiguous — problems that become critical during interoperability and data exchange. The workflow described here:
-
Lowers the barrier for non-ontology experts to contribute high-quality data.
-
Aligns diverse domain perspectives into a single, coherent property model.
-
Ensures that the transition from human insight to machine reasoning is seamless.
From methodology to implementation¶
This section explains how the method (from Property description model to Guided workflow) yields concrete, reusable implementation artifacts — while keeping the technical detail out of scope for this specification.
Modeling patterns from Method to Reuse¶
Each recurring solution is captured as a Modeling Pattern with:
-
Purpose & Scope (which CQs it satisfies; which property types it serves),
-
Parameterization (required vs. optional fields),
-
Meta-model fragment (abstract structure; no code),
-
Instantiation example (human-readable),
-
Validation hooks (which constraints must be enforced),
-
Standards mapping (how the pattern aligns with ISO 10303, DEXPI, CFIHOS, IEC 61360, etc.).
Validation artifacts¶
From each modeled property (and pattern instantiation), two validation layers are produced:
-
Human-readable specification sheet (for review, approval, onboarding).
-
Machine-readable constraints (e.g., SHACL shapes) to enforce:
-
data type and format,
-
quantity kind & unit compatibility,
-
value domain conformance (enumerations, ranges, regex),
-
lifecycle applicability,
-
reference property integrity (target class, selection scope),
-
calculation/derivation preconditions.
Semantic axioms¶
Generating OWL axioms is optional and only relevant when automated reasoning is required — for example, to infer unit/quantity kind compatibility, subproperty relations, or cross-standard equivalences. Where beneficial, OWL axioms can be generated to support reasoning (e.g., unit/quantity alignment, subproperty relations, equivalence across standards). This document references such axioms but does not embed them; delivery occurs via the external Git repository.
Packaging and delivery¶
To maximize adoption without locking into a single stack, we provide:
-
Human-readable: PDFs/HTML spec sheets; CQ answer bundles.
-
Machine-readable: SHACL shapes, JSON-LD contexts/profiles, mapping tables, and (optionally) OWL.
-
Repository setup: versioned in a public Git (with tags/releases); change logs tied to governance metadata.
Conformance levels¶
To accommodate different maturity levels and organizational contexts, the framework adopts a Profile Approach: each conformance level defines a named profile that implementers can declare and validate against independently. A profile bundles a specific set of required PDM elements, applicable CQs, and SHACL shapes, allowing tools and repositories to advertise and verify their level of compliance without requiring full framework adoption from the outset.
-
Level 1 (Descriptive) — Identification, definition, and minimal value structure present; basic validation.
-
Level 2 (Validated) — Full value structure (quantity/unit/constraints), lifecycle context, and complete governance; SHACL passes.
-
Level 3 (Harmonized) — Mappings to one or more standards plus reference-property alignment; ready for cross-standard interoperability.
Scope reminder: Relations¶
As established in Core elements of the property description model, only Reference Properties are modeled within property definitions. Structural or functional relationships (e.g., part-of, functional dependencies) are out of scope for the property model itself and are handled by the hosting data model/ontology.
Units and quantity kinds policy¶
This section states the framework’s normative baseline for representing physical quantities, units, and measurement scales. It is grounded in the property decomposition use case and in contributions by Heiner Temmen (April 2026).
QUDT as the unit and quantity kind reference¶
The Quantities, Units, Dimensions, and Types Ontology (QUDT) is the reference baseline for units and quantity kinds in this framework. All unit values in Knowledge Ontology and Integration Ontology instance data MUST reference QUDT unit individuals (namespace http://qudt.org/vocab/unit/). Where a required unit or quantity kind is absent from QUDT, an extension ontology MAY define it, with a stated alignment back to QUDT or ISO 80000. QUDT is chosen, because it aligns with ISO 80000 (International System of Quantities) and SI, it is machine-readable and openly available, and it is already used in DEXPI, which references QUDT for property unit attribution.
Project extensions and alignment ontologies for QUDT¶
Within the Arrowhead fPVN project, three ontology artifacts were developed to bridge QUDT with IDO and to address industrial units and quantity kinds not yet present in the standard QUDT release:
QUDT-IDO Alignment Ontology
: Creates alignment axioms mapping qudt:Unit to lis:Scale and restricting the domain of qudt:hasQuantityKind to lis:PhysicalQuantity. This is the approach adopted in the project; however, the alignment itself is still under discussion, and other approaches are being evaluated.
QUDT Unit Extension Ontology
: Introduces missing unit individuals required for industrial applications — in particular unit:BAR_GAUGE and unit:MilliBAR_GAUGE for gauge pressure. Gauge pressure units require a variable atmospheric-pressure offset that stock QUDT units do not carry; the extension proposes a mechanism to incorporate a conversionOffset into unit metadata. This extension is a pending change request that has not yet been formally submitted to the QUDT maintainers.
QUDT Quantity Kind Extension Ontology
: Adds missing quantity kind individuals to QUDT’s hierarchy for industrial use cases, including qudt:AbsolutePressure (distinct from generic qudt:Pressure). This extension is also a pending change request that has not yet been formally submitted.
Note
Until these extensions are accepted upstream, consuming ontologies MUST declare them in a project-scoped namespace and document the intended alignment with stock QUDT individuals. See Pressure variants: gauge vs. absolute for the modeling implications.
Quantity kind vs. unit — the required distinction¶
A physical quantity (quantity kind) and a unit are distinct concepts that must both be modeled explicitly:
-
The physical quantity (e.g., Pressure, Absolute Pressure, Gauge Pressure) classifies what is measured. It is assigned to the property definition and is independent of the choice of unit.
-
The unit (e.g., Pa, bar, psi) specifies how the numeric value is scaled. It is assigned to each value individual, not to the property definition.
Consequence: a property definition such as Design Pressure includes exactly one physical quantity (Gauge Pressure). This fixes the interpretation of all values of that property as relative pressure, regardless of which unit (bar, psi, kPa) the numeric value is expressed in. This follows Rule R7 of the decomposition model: if a property is assigned to a physical quantity and no unit is specified, all units defined for that physical quantity in the applicable system of units (e.g. SI) apply.
Pressure variants: gauge vs. absolute¶
In the process industry, the physical quantity Pressure has two important specializations that must be distinguished at the property definition level — not at the unit level (Table 4):
| Physical quantity | Definition | Typical use |
|---|---|---|
| Absolute Pressure | Pressure measured relative to a perfect vacuum (zero reference). Equals the sum of atmospheric pressure and gauge pressure. | Differential Pressure properties (e.g., pressure difference across a pump) |
| Gauge Pressure (overpressure) | Pressure measured relative to the surrounding atmospheric pressure. Indicates how much pressure is above or below ambient. | Design Pressure properties (e.g., per API 610, ASME B31.3) |
Implication for modeling: two properties that both use the unit bar but refer to different physical quantities (Absolute Pressure vs. Gauge Pressure) are not interchangeable. Each property definition must state which physical quantity applies. Mixing them without explicit conversion is a semantic error.
For gauge pressure units specifically, stock QUDT (e.g., unit:BAR) does not encode the atmospheric reference offset. The QUDT Unit Extension Ontology developed in this project introduces unit:BAR_GAUGE and unit:MilliBAR_GAUGE to make this offset explicit (see Project extensions and alignment ontologies for QUDT). Until these units are accepted upstream, implementations using gauge pressure MUST reference the project-scoped extension namespace and document the offset convention.
Scale type constraints on numeric values¶
The scale type of a physical quantity constrains the permissible numeric values:
-
Ratio scale (e.g., Absolute Pressure in Pa or bar): values must be non-negative (zero = absolute vacuum).
-
Interval scale (e.g., temperature in °C): negative values are permissible; zero is arbitrary.
-
Logarithmic scale (e.g., sound level in dB): equal differences on the scale correspond to multiplicative differences in the quantity.
Validation rules (SHACL shapes) for a property MUST reflect the scale type of its physical quantity.
Competency Questions¶
This section defines 13 Harmonization Aspects, each articulated as __Competency Questions (CQs) that guide experts in eliciting complete information about every property across standards. By systematically answering these CQs for each property and standard, experts ensure no information gap remains.
Identification and labeling¶
Use Case: An expert must be able to unambiguously point to a property across all systems.
-
CQ-1.1 What is the globally unique identifier (code, URI, key) for this property?
-
CQ-1.2 What human-readable name and definition do we give it?
-
CQ-1.3 What legacy or alternate identifiers/aliases have been used in other standards or tools?
-
CQ-1.3a For each identifier/alias, which standard/tool used it, and during what time period?
-
CQ-1.3b Is an identifier scheme (e.g. UUID, IRDI, database key) defined?
-
CQ-1.3c Is there a reference to the identifier in another lifecycle?
Data type and value domain¶
Use Case: An expert must know exactly what form and range of data is acceptable.
-
CQ-2.1 Which basic data type does this property use? (e.g. Boolean, integer, decimal, text, date/time, enumeration)
-
CQ-2.2 What values are allowed? Is it a continuous range, a fixed list, a pattern (e.g. regex), or something else?
-
CQ-2.2a If range-based, is the interval open, closed, or half-open?
-
CQ-2.3 If it’s an enumeration, what are all the permissible options and how are they labeled or coded?
-
CQ-2.3a Is enumeration structured (e.g. hierarchically)?
-
CQ-2.3b Do codes have numeric equivalents or localized labels?
-
CQ-2.3c How should unknown enumeration values be handled (extensibility)?
-
CQ-2.4 Are there limits on how many instances (cardinality) or format rules that apply?
-
CQ-2.5 Are default units implied when none are specified?
QuantityKind and unit¶
Use Case: An expert must be sure that a unit is completely defined (from a physical perspective), and that any unit conversion is handled correctly.
-
CQ-3.1 What physical or logical quantity does this value represent? (e.g. the physical quantities voltage and electrical potential both have the unit volt)
-
CQ-3.1a Which dimension vector has the physical quantity?
-
CQ-3.2 Which unit(s) of measure are allowed, and how do we convert between them?
-
CQ-3.3 Are custom or non-SI units permitted, and if so, with what conversion rules?
-
CQ-3.3a Is there a preferred SI representation or a legacy "engineering unit"?
Lifecycle context¶
Use Case: An expert must track how a property’s meaning or value changes over a project’s phases.
-
CQ-4.1 In which project or asset-lifecycle phases is this property defined or valid? (Idea, Specification, Design, Build, Commissioning, Operation, Maintenance, Decommissioning)
-
CQ-4.2 Does this property have different recorded values in different phases? If so, what are they?
-
CQ-4.3 Are there formal rules for how a value transitions from one phase to the next?
Provenance and governance¶
Use Case: An expert must know who defined a property, when, and under what authority.
-
CQ-5.1 Which standard (and version) or source document defines this property?
-
CQ-5.2 Who authored or maintains it, and when was it created or last modified?
-
CQ-5.3 What is its review or approval status (Draft, Reviewed, Approved, Obsolete)?
-
CQ-5.4 How is an update or version change documented?
Relationships and constraints¶
Use Case: An expert must capture dependencies or formulas that tie multiple properties together.
-
CQ-6.1 Does this property depend on or derive from one or more others? Which ones, and how?
-
CQ-6.2 Are there algebraic or logical rules (e.g. formulas, thresholds) that govern valid combinations?
-
CQ-6.3 Is this property part of a composite or logical grouping? Which other properties belong with it?
Classification and domain scope¶
Use Case: An expert must classify each property by discipline and industry taxonomy.
-
CQ-7.1 Which engineering domains or disciplines use this property? (Mechanical, Electrical, Process, Building, Medical, Safety, etc.)
-
CQ-7.2 Under which classification schemes or code lists (e.g. reference designation, product class) does it fall?
-
CQ-7.3 Is it mandatory or optional in each context?
Intended and actual use¶
Use Case: An expert must understand both the original purpose of a property and how it’s actually reused in the field.
-
CQ-8.1 For what scenario or use case was this property originally designed?
-
CQ-8.2 How has it been repurposed or overloaded in real-world implementations?
-
CQ-8.3 Are there conflicts or mismatches between its intended and actual uses?
Technical representation and packaging¶
Use Case: An expert must know where and how this property appears in each standard’s deliverable.
-
CQ-9.1 In which file format or schema (e.g. EXPRESS module, XML schema, JSON-LD context) is the property defined?
-
CQ-9.2 Under what module, part, or template grouping does it live?
-
CQ-9.3 How would you map it into our harmonized information model?
Data quality and accuracy¶
Use Case: An expert must specify precision, accuracy, defaults, and null-handling for data consumers.
-
CQ-10.1 What precision or number of significant digits is required?
-
CQ-10.2 What measurement accuracy or error bound applies?
-
CQ-10.3 Is there a default or typical value when none is provided?
-
CQ-10.4 How should missing or "not-applicable" values be represented?
Localization and presentation¶
Use Case: An expert must prepare properties for multi-language and user-friendly display.
-
CQ-11.1 Which language variants are needed for name and description?
-
CQ-11.2 How should the value be formatted in different locales (decimal separators, date formats, unit placement)?
-
CQ-11.3 Are there icons or domain-specific symbols that aid user interpretation?
Lifecycle management and deprecation¶
Use Case: An expert must manage the evolution and retirement of properties over time.
-
CQ-12.1 Is this property deprecated or superseded?
-
CQ-12.2 If so, what is the target replacement, and when will the old one be retired?
-
CQ-12.3 Are there migration guidelines for migrating existing data to a new property?
Security and privacy classification¶
Use Case: An expert must mark sensitive data and enforce access rules.
-
CQ-13.1 Does the property contain confidential or regulated information?
-
CQ-13.2 What access control rules govern who can read or write it?
-
CQ-13.3 Is encryption or masking required in storage or transmission?
Ontology architecture¶
So far, it has been elaborated that the knowledge about a property can essentially be assigned to the following aspects:
-
the assignment of the property to its bearer object,
-
the property itself,
-
the possible values that a property can take, and
-
the assignment of the values to the property.
This decomposition makes it possible to make the knowledge of experts explicitly available in semantic and structured form. In this way, properties from different standards can be harmonized. This explicit decomposition of knowledge makes use of reification. However, reification causes complex structures for instance data in integration scenarios. In ontologies intended for use in integration scenarios, owl:ObjectProperties or owl:DatatypeProperties are preferred. In ISO 23726-1, the derivation of owl:ObjectProperties or owl:DatatypeProperties from reified properties is referred to as a shortcut.
Types of ontologies¶
The framework distinguishes three ontology types that serve complementary roles in the overall architecture. A Knowledge Ontology captures harmonized, application-independent property definitions using full reification; an Integration Ontology resolves reification into owl:ObjectProperty assertions to simplify data access while preserving traceability back to the knowledge layer; and a Data Model Ontology represents the structure of a specific data source or consumer using owl:DatatypeProperty assertions, providing the mapping bridge into the integration layer. Each type addresses a different point in the path from expert knowledge to machine-readable instance data.
Knowledge ontology¶
So far, we have pursued the purpose of "explicit and harmonized knowledge collection" by means of ontologies. Here, "harmonized" means "application-independent" as defined in ISO 23726-1. Such an ontology could be referred to as a Knowledge Ontology.
Definition: An ontology that serves the purpose of semantically explicit, harmonized, and application-independent knowledge collection from a well-defined domain of knowledge is called a Knowledge Ontology. In such ontologies, properties are modeled as classes (reification).
Instance data for a Knowledge Ontology are complex. Concretely, to reach the value assigned to a specific object instance, several steps are required: from the bearer object instance to the property instance to the value instance to the value itself.
Integration ontology¶
The main difference between a Knowledge Ontology and an Integration Ontology is the path to get from the bearer object to the value. In an Integration Ontology, reification of the property is resolved by deriving at least one owl:ObjectProperty from the corresponding Property class defined in a Knowledge Ontology.
On the other hand, an Integration Ontology can also serve as the basis for creating missing or incomplete Knowledge Ontologies by making implicit knowledge in the Integration Ontology explicit, transferring it into the appropriate Knowledge Ontology, and establishing the back-link to the now explicitly available knowledge in the Knowledge Ontology.
Definition: An ontology that provides semantics for an application-independent Knowledge Graph to enable uniform integration of heterogeneous data sources is called an Integration Ontology. In such ontologies, properties are modeled as owl:ObjectProperties. The owl:ObjectProperties defined in an Integration Ontology should be linked to properties from a Knowledge Ontology to ensure that the knowledge about the property is fully and explicitly available.
Instance data for an Integration Ontology are simpler than for a Knowledge Ontology. Concretely, to reach the value assigned to a specific object instance, only the following steps are needed: from the bearer object instance to the value instance to the value itself.
Data model ontology¶
In order to integrate data sources into a semantic integration landscape, or to consume application-independent instance data from an application-independent Knowledge Graph, it may be appropriate to represent the data structure of the source or the consumer as an ontology. Such an ontology would thus serve as the basis for mapping data from the source or the consumer to the application-independent instance data in the Knowledge Graph.
Definition: An ontology that serves to describe the data structure of a data source or a data consumer is called a Data Model Ontology. In such ontologies, properties are modeled as owl:DatatypeProperties. The owl:DatatypeProperties defined in a Data Model Ontology should be linked to the corresponding owl:DatatypeProperties from an Integration Ontology in order to enable the mapping to application-independent data communication.
Instance data for a Data Model Ontology are simpler than for a Knowledge or an Integration Ontology. Concretely, to reach the value assigned to a specific object instance, only one step is required: from the bearer object instance directly to the value itself.
Unified property reification model¶
IDO’s core reification mechanism — representing properties as first-class individuals rather than plain datatype attributes — provides the foundation for attaching rich metadata to any property value. This section describes the proposal (Onno Paap / CFIHOS Semantics, 2025–2026) to extend this mechanism uniformly across all property types, not only quantifiable ones.
The motivation: uniform metadata attachment¶
In a typical industrial data set, properties span multiple types: measurable quantities (pressure, temperature, flow rate), identifiers (tag number, document ID), references to external objects (manufacturer, material grade), and free-text descriptions. In a minimal RDF representation, these are naturally expressed as different triple patterns:
-
Quantifiable:
pump → hasQuality → [Quality] → qualityQuantifiedAs → [Datum] -
Identifying:
pump → rdf:type → [Class]orpump → tagName → "11P-101"^^xsd:string -
Reference:
pump → manufacturer → org:ABB
If each type is handled differently — some reified, others as simple datatype or object property assertions — then provenance, data maturity, confidence level, and lifecycle stage metadata can only be attached to some properties. This creates fragmentation: a "design pressure" value can carry full traceability, but the tag name and manufacturer reference cannot. In complex industrial data sets such as CFIHOS (10,000+ properties of all types), this inconsistency breaks automated validation and cross-system alignment.
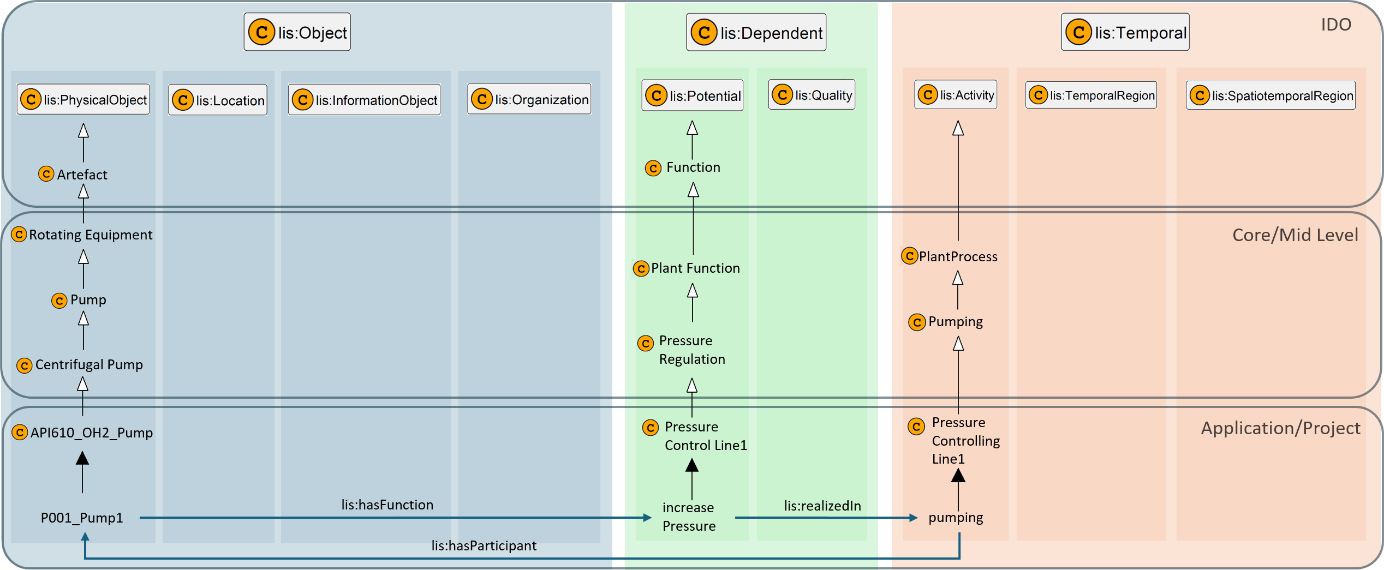
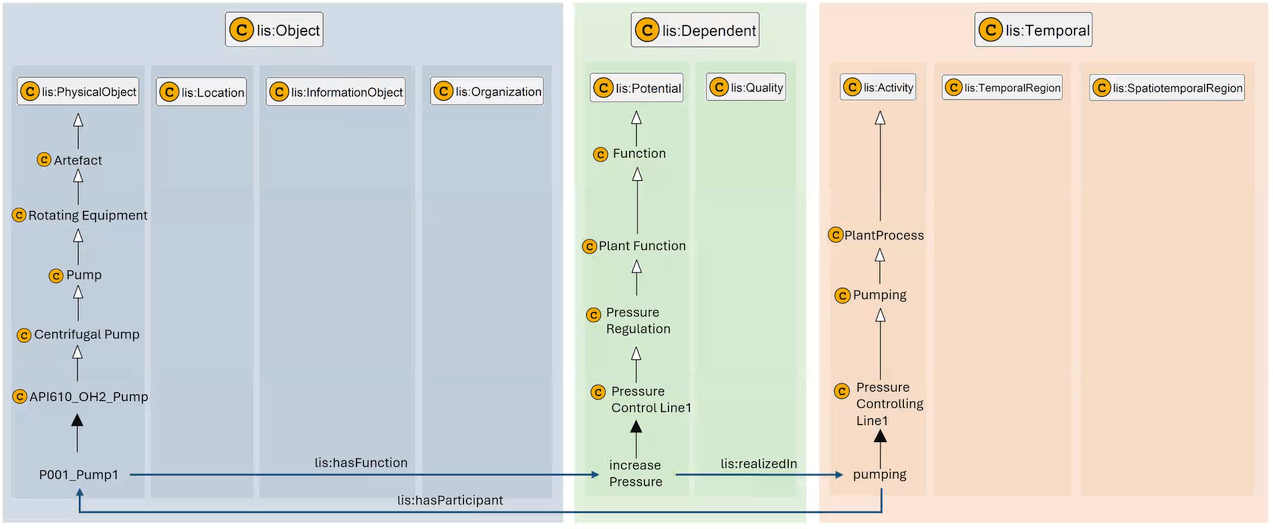
The Layered Modular Ontology Architecture illustrated in Figure 6 — showing the full taxonomy from Artefact to P001_Pump1 and the functional chain across Object, Dependent, and Temporal — makes the scope of this problem concrete: at the Application/Project level, a pump instance (P001_Pump1) carries properties from all three branches simultaneously — quantifiable design properties, an identifying tag number, and reference relationships to manufacturers and standards bodies. All must be uniformly queryable and validatable.
Figure 7 makes explicit which IDO tripartite branch (Object / Dependent / Temporal sub-types) belongs to: quantifiable properties sit in lis:Dependent (lis:Quality); identifying properties (tag name, document ID) sit in lis:Object (lis:InformationObject); reference relations connect objects across the Object branch. This column structure maps directly to the three-row table in Worked examples below.
Worked examples¶
The following three examples (Table 5) illustrate the unified pattern across the main property branches. All use the same structural skeleton: bearer → property individual → datum individual → value or reference.
| Property type | Example | Reified triple pattern |
|---|---|---|
Quantifiable |
Centrifugal pump has upper-limit design pressure of 15 bar |
|
Identifying |
Centrifugal pump has tag name "11P-101" |
|
Reference |
Centrifugal pump is manufactured by Blog & Co |
|
In all three cases, the intermediate individual (ex:UpperDesignPressure-01, ex:TagName-01, ex:ManufRel-01) is an addressable node in the knowledge graph. Metadata — data owner, responsible discipline, data maturity status, revision date, provenance source — can be attached to this node uniformly across all property types using the same annotation pattern.
OWL class restrictions for allowable properties¶
A key requirement of CFIHOS is that each equipment class specifies which properties are permissible for its instances. This class-to-property binding is expressed using OWL restrictions on the bearer class:
:CentrifugalPump rdfs:subClassOf [
a owl:Restriction ;
owl:onProperty lis:hasQuality ;
owl:someValuesFrom :UpperLimitDesignPressure
] .
:UpperLimitDesignPressure rdfs:subClassOf [
a owl:Restriction ;
owl:onProperty lis:qualityQuantifiedAs ;
owl:allValuesFrom lis:DoubleMeasureTypeDatum
] .
The first restriction states that every CentrifugalPump instance must have at least one UpperLimitDesignPressure quality. The second constrains the datum type, enabling type-safe unit checking. These restrictions can be validated with SHACL shapes derived directly from the OWL axioms. The same mechanism applies to Designation and ObjectRelation allowable properties.
Shortcut properties¶
Where integration ontologies or downstream consumers require simpler access patterns, shortcut properties (owl:DatatypeProperty or owl:ObjectProperty) can be derived from the reified form. A shortcut property collapses the bearer → individual → datum → value chain into a single triple:
ex:Pump-X1 :designPressureBar 15 .
The shortcut must carry an annotation (rdfs:seeAlso or a dedicated provenance property) linking it back to the Knowledge Ontology class that defines its full semantics. This preserves traceability and is consistent with IDO’s Knowledge → Integration → Data Model layer hierarchy (Types of ontologies). Shortcuts are not the authoritative record; they are derived views.
IDO v4.2: TemporalDatum¶
IDO v4.2 (FDIS) extends the reification model with lis:TemporalDatum for property values intrinsically linked to a specific activity or time context — for example, "maximum pressure during the commissioning activity" or "cumulative operating hours since last inspection". TemporalDatum fits natively into the unified model as a specialization of the datum individual:
ex:CommissioningActivity lis:hasTemporalRegion ex:CommRegion-01 .
ex:CommRegion-01 lis:temporalRegionQuantifiedAs ex:CommDuration-01 .
ex:CommDuration-01 a lis:TemporalDatum ;
lis:temporalValue "P14D"^^xsd:duration .

Figure 8 summarizes all conceptual changes in IDO v4.2. The Time as quantity row (trigger NO-117) confirms the canonical TemporalDatum pattern shown above. Note also the InformationObject vs BFO GDC row (FR-078): lis:InformationObject is confirmed as a subclass of lis:Object (independent), not of lis:Dependent — which is the basis for the Designation branch of the unified model: tag names and document identifiers are information objects, not inherent qualities.
Note
The formal OWL patterns, Turtle examples, and SHACL shapes for all property branches of this model are defined in Property Classes Pattern. Instance data architecture decisions --- which ontology layer to instantiate for which use case --- are in Instance data architecture.
Instance data architecture¶
Ideally, it would be useful to have instance data in the form of Knowledge Graphs for each of the ontology types defined above. However, this would lead to redundancies in instance data. Therefore, a practical instance data architecture should be developed. A general recommendation cannot be given here, as this depends strongly on the use cases, which are not known in this context.
The following questions can serve as criteria for designing such an architecture (without claiming completeness):
-
Which use cases require the details from Knowledge Ontologies?
-
For the use cases identified under 1, is it necessary to use the instance data based on Knowledge Ontologies (direct access of the explicit knowledge defined in the Knowledge Ontology) or could it be enough to have only the Instance data based on Integration Ontologies (indirect access to the knowledge defined in the Knowledge Ontology via the backlink from the
owl:ObjectPropertydefined in the Integration Ontology to the class defined in the Knowledge Ontology)? -
Which use cases require the details from Integration Ontologies?
-
For the use cases identified under Motivating scenarios, is it necessary to use the instance data based on Integration Ontologies?
-
Where and how should the mapping of data from the sources or the data to be consumed to the instance data based on Integration Ontologies be performed?
Class structure ontology¶
For various reasons, which are not relevant in this context, properties are grouped together and often have a fixed predefined order within the group. Examples include:
-
Blocks and Aspects in ECLASS
-
Attribute Category and Attribute Sub-Category in the Digital Product Passport
-
Property Groups in data sheets
-
Submodels in the Asset Administration Shell
Such groupings can be regarded as application-specific views on the properties defined in the application-independent Knowledge Ontologies or Integration Ontologies. In such groupings, attributes may be required that are not necessary in Knowledge or Integration Ontologies and therefore are not defined there. An example is the number of Properties in ECLASS.
Property groupings can also be hierarchical. That means one group can be part of another group. For example, blocks in ECLASS can contain properties that refer to another block; in the Digital Product Passport properties are structured as Attribute Category and Attribute Sub-Category. This allows the properties of a class to be finely structured.
Definition: An ontology that defines a specific and possibly fine-grained view on the properties of classes defined in a Knowledge or Integration Ontology is called a Class Structure Ontology.
Class Structure Ontologies provide application-specific views and are therefore not part of application-independent Knowledge or Integration Ontologies. Such fine-grained structuring may include both a predefined order and a hierarchical grouping.
Responsibilities / versioning¶
Domain experts are typically specialized in certain subject areas. It is therefore reasonable to group properties according to these subject areas, with clearly defined expert groups being responsible for their maintenance and further development. Such a division of responsibilities ensures that different expert groups can work in parallel and independently, while still maintaining overall consistency across the framework.
In principle, properties should remain stable once defined. However, practical requirements and evolving standards will inevitably lead to modifications. This necessitates versioning mechanisms that allow new versions of properties or property groups to be introduced without invalidating existing data. Responsibilities and versioning must therefore be organized in such a way that property changes are transparent and traceable, existing Knowledge and Integration Ontologies remain backward-compatible, and new versions can be integrated into the Knowledge Graph without disrupting ongoing use cases. This approach ensures that the framework remains both stable and adaptable, enabling long-term maintenance and evolution of the Knowledge Graph.
The pattern library¶
The previous sections have shown that complex domains of knowledge can be modeled using different ontology types and integrated into a consistent overall system. This section forms the transition from the conceptual foundation (from Methodology to Ontology architecture) to a practically usable Pattern Library. For each pattern, the assignment of its elements to the appropriate ontology types, and the connections across those ontology types, must be specified.
The term "pattern" is used here in accordance with the definition in ISO 23726-1 (Clause 3.3.3).
This library serves as a "toolbox" that provides predefined patterns for recurring modeling and integration tasks. The goal is to reduce the effort for modelers, ensure consistency across the ecosystem, and build a bridge between theory and application. The Pattern Library therefore fulfills three central functions:
-
Structuring: It provides a uniform template for documenting individual patterns.
-
Linking: Each pattern is linked back to concepts from Methodology through Ontology architecture and to the principles defined in ISO 23726-1 Overview and fundamental principle.
-
Application: It enables reuse in concrete modeling and integration projects, independent of the application domain.
Documents in the pattern library¶
There are different purposes a pattern is intended to serve. To cover all purposes, at minimum the documents defined in the following subsections should be provided and maintained for each pattern. Table 6 shows which deliverables are required for each ontology type.
| Deliverable | Knowledge | Integration | Data Model | Class Structure |
|---|---|---|---|---|
| Pattern documentation | ✓ | ✓ | ✓ | ✓ |
| Foundational building-block ontologies (.ttl files) | ✓ | ✓ | ○ | ○ |
| Turtle files with pattern application examples (OWL + SHACL) | ✓ | ✓ | ✓ | ✓ |
| Executable pattern validation algorithm | ✓ | ✓ | ✓ | ✓ |
| Executable pattern generation algorithm (Knowledge → Integration) | ✓ | ✓ | — | — |
✓ = required; ○ = as needed; — = not applicable
Pattern documentation¶
Detailed verbal and, where appropriate, graphical description of a pattern. The expected sections of a pattern documentation are described in the next section.
Foundational building-block ontologies as .ttl files¶
If components required by a pattern — such as classes, relations, or axioms — are missing in IDO or other available ontologies, they must either be added to existing IDO-aligned ontologies or new foundational building-block ontologies must be created.
Turtle files with pattern application examples¶
Pattern application examples should, where possible, show typical, use-case-related examples of how patterns are to be applied in knowledge and integration ontologies. These examples should meet the following requirements:
-
Turtle syntax is used.
-
Each example is modeled in both OWL and SHACL.
-
OWL and SHACL are stored in separate files.
Executable pattern validation algorithm¶
Pattern validation algorithms serve to validate modeling in knowledge and integration ontologies. Such an algorithm should contain executable code that ensures the rules defined in the pattern documentation are adhered to consistently. Preferably, validation should be encoded in SHACL. If SHACL is not sufficient, SPARQL can be used within the SHACL shapes.
Executable pattern generation algorithm¶
An algorithm for generating the pattern for an integration ontology from the pattern in a knowledge ontology is referred to as a pattern generation algorithm. Such an algorithm should be directly executable — preferably in Python
Basic structure of the pattern documentation¶
To ensure consistency and reusability, every pattern follows a uniform documentation structure. The sections of a pattern documentation are:
-
Name and Identifier: Unique designation of the pattern.
-
Purpose and Motivation: Description of what is addressed by the pattern.
-
Competency Questions: Which competency questions are needed to elicit expert knowledge, and which competency questions can be answered by the pattern?
-
Context of Use (thematic): In which scenario is the pattern typically applied? How is this context of use delimited from other contexts of use?
-
Context of Use (ontology type): In which ontology types can the pattern (or only parts of it) be used?
-
Structure and Elements:
-
Compilation of the elements of a pattern, with references to sources such as the upper ontology, building-block ontology, and, where applicable, other ontologies.
-
Compilation of the variables. A variable serves to capture, in a standardized form, the knowledge that is to be recorded with this pattern. Therefore, each variable must be described in detail. The description must explain which part of the competency question is answered by the variable. Constraints such as predefined values must be described in detail.
-
Detailed construction of the pattern by assembling the aforementioned elements in Turtle syntax. Add comments if required.
-
The above points apply both to the pattern for knowledge ontologies and to the pattern for integration ontologies. Each element and each variable should be defined only once. It should be indicated for which ontology type a variable is intended.
-
Examples: An overview of the examples and references to the associated Turtle files with pattern application examples
-
Links to Other Patterns: If references to related or complementary patterns exist, then they should be described in detail.
-
Description of the Pattern Validation Algorithm: Detailed verbal description of the algorithm by which it can be checked that the rules for applying a pattern in a knowledge and/or integration ontology are strictly followed. References to the files containing the associated executable pattern validation algorithm should be included.
-
Description of the Pattern Generation Algorithm: Detailed verbal description of the algorithm by which, from a concrete pattern defined in a knowledge ontology, the corresponding pattern in an integration ontology can be generated. References to the associated files with the executable pattern generation algorithm should be included.
Pattern-to-CQ mapping¶
Each pattern addresses one or more Competency Questions from Competency Questions. Table 7 maps approved and candidate patterns to the 13 Harmonization Aspects, enabling implementers to navigate from an information need directly to the relevant pattern(s).
Note
The table will be populated as patterns are approved and added to the library.
| Pattern ID | CQ-1 Id. |
CQ-2 Val. |
CQ-3 QK/U |
CQ-4 LC |
CQ-5 Gov. |
CQ-6 Rel. |
CQ-7 Class. |
CQ-8 Use |
CQ-9 Rep. |
CQ-10 Qual. |
CQ-11 L10n |
CQ-12 LCM |
CQ-13 Sec. |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
(to be populated) |
CQ-1 Identification & labeling; CQ-2 Data type & value domain; CQ-3 QuantityKind & unit; CQ-4 Lifecycle context; CQ-5 Provenance & governance; CQ-6 Relationships & constraints; CQ-7 Classification & domain scope; CQ-8 Intended & actual use; CQ-9 Technical representation; CQ-10 Data quality & accuracy; CQ-11 Localization & presentation; CQ-12 Lifecycle management & deprecation; CQ-13 Security & privacy.
Pattern index¶
Note
This section will list all approved and candidate patterns in the library, organized by category and aspect. It is currently empty pending the first set of pattern approvals.
Governance and lifecycle management¶
Each pattern must include explicit governance attributes: versioning, source of definition, approval status, and ownership. These ensure sustainable maintenance and controlled evolution of the Pattern Library.
Pattern lifecycle status model¶
Every pattern carries one of the following lifecycle states as shown in Table 8:
| Status | Meaning | Entry / exit criteria |
|---|---|---|
Draft |
Pattern is under development; not ready for review. |
Entry: contributor submits a proposal with at least Name, Purpose, and one CQ addressed. |
Candidate |
Pattern is under formal review by the working group. |
Entry: working group accepts the review request. |
Approved |
Pattern is normative; may be referenced in implementations. |
Entry: working group approval vote passes. |
Deprecated |
Pattern is superseded or withdrawn; retained for traceability. |
Entry: Approved pattern is replaced by a newer version or found incorrect. |
Typical triggers for versioning or deprecation include changes in upstream ontologies (IDO, QUDT), revision of the addressed Competency Questions, or availability of a more general or better-validated replacement pattern.
Note
The formal proposal, review, and acceptance process --- including voting rules and responsible bodies --- is to be confirmed with PCA. This section will be updated once that information is available.
Role in the overall document¶
With the Pattern Library, the conceptual derivation comes to an end. It provides the bridge to practical application:
-
From Methodology to Ontology architecture: Development of the conceptual and methodological foundations.
-
This section: Operationalization of these foundations in reusable patterns.
-
Subsequent pattern documents (outside this guideline document): Detailed description and continuous extension and maintenance of the library.
Lifecycle modeling¶
A lifecycle is the complete process an entity undergoes from its creation to its end-of-life, often broken down into phases. Common lifecycle models include:
-
Product lifecycle: Concept → Design → Development → Production → Use → Disposal
-
Software/system lifecycle: Requirements → Design → Implementation → Testing → Deployment → Maintenance → Retirement
-
Data lifecycle: Creation → Storage → Usage → Sharing → Archiving → Deletion
-
In semantic or knowledge graph contexts, a lifecycle may refer to:
-
The evolution of entities (e.g., a product or component) over time.
-
The traceability of changes across different representations (e.g. functional vs. physical).
-
The alignment of ontologies or schemas across lifecycle stages.
Lifecycle approaches in context¶
Multiple established industrial standards address the lifecycle of assets. Rather than introducing a new lifecycle model, this framework identifies the common structure across existing frameworks and uses it as a shared reference for property governance (Table 9).
| Framework | Primary domain | Key lifecycle stages |
|---|---|---|
CFIHOS |
Capital facilities information handover |
FEED → Detail Design → Construction → Commissioning → Operation |
DEXPI |
Process plant P&ID, piping, instrumentation |
Engineering → Handover → Operation |
IMF / DISC |
Systems engineering, function decomposition |
Concept → Design → Realization → Operation → Decommission |
IFC (BIM) |
Buildings and infrastructure |
Concept → Design → Construction → Operation → Demolition |
ISO/IEC 81346 |
Reference designation system |
Not time-ordered; orthogonal aspects: Functional / Physical / Locational |
Arrowhead WP9 |
Pump station engineering |
Need Assessment → Design → Procurement → Construction → Commissioning → Operation → Upgrades → Decommissioning |
Despite differences in terminology and granularity, these frameworks converge on the same fundamental sequence: specification/intent → realization/construction → operation → end-of-life/decommissioning. The variation lies in how handover milestones are named and subdivided, not in the underlying conceptual structure.
A comparison of CFIHOS, DEXPI, and IMF/DISC (Heiner Temmen, DEXPI e.V., March 2026) confirms that their lifecycle approaches are broadly aligned: CFIHOS and DEXPI are primarily concerned with plant engineering and handover phases; IMF/DISC addresses systems engineering function decomposition. ISO/IEC 81346 is orthogonal — it organizes objects by reference designation aspects (Functional, Physical, Locational) rather than by time-ordered phases, but its functional/physical distinction maps directly onto the V-model framing described in The three-world model.
A pump instance (P001_Pump1) at Application/Project level simultaneously carries properties from the specified plant (design specifications) and the realized asset (operational measurements). Each row in the left-hand taxonomy corresponds to a layer of lifecycle abstraction.
Implication for property modeling: A property value is not context-free. "Design pressure" and "measured operating pressure" refer to the same physical quantity but belong to different lifecycle phases with potentially different values, different governance rules, and different validation criteria. The framework models these as phase-aware property instances, not as separate property classes (see Lifecycle context).
The three-world model¶
Process industry lifecycle modeling can be organized around a V-model with two orthogonal axes (Heiner Temmen, DEXPI e.V., March 2026):
-
Planned ↔ Realized: The horizontal axis separates design intent (what the system should be) from realized actuality (what the system is as built).
-
Functional ↔ Technical/Physical: The vertical axis separates what a system does (its purpose and behavior) from what it physically is (its components and structure).
The resulting four quadrants can be laid out as a flat matrix before collapsing them into the V-shape. Figure 10 shows this flat view: the rows distinguish FunctionalEntity from TechnicalEntity; the columns distinguish Specified (planned) from Actual (realized). The horizontal arrows (isPlanFor / isRealizedBy) and vertical arrows (hasSolution / isImplementedBy) name the bridging relations that connect adjacent quadrants.
The same four quadrants can be reorganized into a V-shape to make the verification/validation flow explicit:
The V-model produces three semantic worlds:
Process world (top of V)
: Activities, streams, and functions. Describes what the system does. Examples: "a pump delivers fluid from suction to discharge"; "a heat exchanger transfers thermal energy between two streams". In IDO, these are lis:Temporal entities — primarily lis:Activity individuals. Process objects and their components are modeled here as a process breakdown structure (following DEXPI Process).
Specified (planned) plant (left side of V)
: Functional and technical entities as design intent. Describes what the system should be. Engineering specifications, equipment class definitions, functional requirements, and process plant breakdowns live here. In IDO these appear as FunctionalEntity and TechnicalEntity class instances. DEXPI Plant and CFIHOS FEED/Design-phase data are anchored in this world.
Actual (realized) asset (right side of V)
: Installed physical objects as built and in operation. Describes what the system is. As-built surveys, maintenance records, operational sensor readings, and asset registration data live here. In IDO these are lis:PhysicalObject individuals.
The relations that link the three worlds:
-
lis:implements— an actual (realized) asset implements a specified (planned) functional or technical entity. -
lis:implementedBy— the inverse ofimplements; a specified entity is implemented by one or more realized assets. -
lis:hasParticipant/lis:participatesIn— physical objects (Object world) participate in activities (Process/Temporal world).
Figure 12 provides a concise visual summary of these two bridging relations across the three worlds.

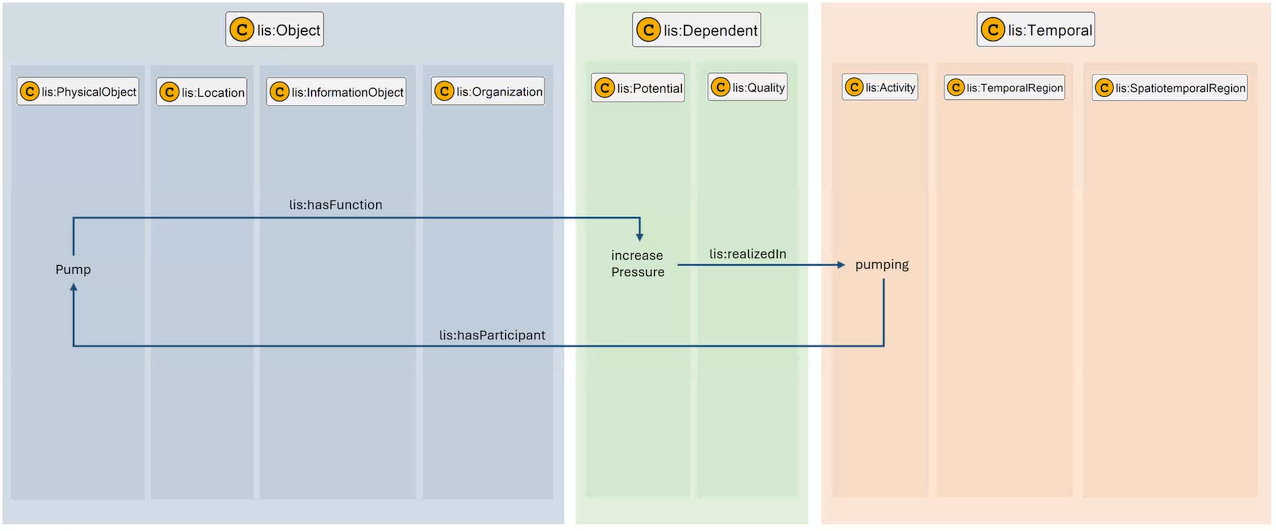
Figure 13 shows the full IDO chain: the pump in the Object world carries a lis:Potential ("increase pressure") via lis:hasFunction; that potential is lis:realizedIn a "pumping" lis:Activity in the Temporal/Process world; and the activity lis:hasParticipant the same pump. This closed loop precisely expresses the structural connection between all three semantic worlds.
Connection to IDO’s tripartite: IDO’s top-level classification (Object / Dependent / Temporal) maps directly onto the three-world model:
-
lis:Object(physical objects) → Realized asset world -
lis:Dependent(properties, potentials) → Bridge between worlds; properties belong to a bearer in the Object world but are governed by specifications from the Planned world -
lis:Temporal(activities, processes) → Process world
Note
Because the same physical quantity may carry different values in different lifecycle phases or worlds --- a design pressure in the Specified world, a measured pressure in the Realized world --- every property value must be tagged with its lifecycle context. This is the role of CQ-4 (see Lifecycle context).
Tag and equipment class distinction¶
In process industry information management, the same physical asset is typically described by two distinct data sets (Onno Paap, FLUOR Engineering, 2025):
Tag dataset
: Properties that describe what was specified for a functional location (tag) in the plant — the engineering intent. A tag such as 11P-101 identifies a functional position, not a physical object. The tag data set contains design requirements (e.g. rated flow, design pressure) and is anchored in the specified plant world.
Equipment dataset
: Properties that describe the physical object installed at that functional location — the as-built reality. The equipment data set contains manufacturer-specific data (model, serial number, actual dimensions) and operational measurements. It is anchored in the actual asset world.
These data sets co-exist, can legitimately diverge (as-built differs from spec), and are governed by different organizations (engineering vs. operations). In the three-world model (The three-world model), the tag belongs to the specified plant; the equipment to the actual asset. The relation cfihos:isFulFilledBy links the two individuals (e.g., tag individual ex:2384 isFulFilledBy equipment individual ex:4387).
In the CFIHOS relational data model there is no strict structural separation: a single table (tag_or_equipment_class) uses boolean indicators to flag whether a class serves as a tag class, an equipment class, or both. The same applies to properties: a single tag_or_equipment_class_property table flags each property as tag-relevant and/or equipment-relevant. Converting this to a semantic model required an explicit modeling decision.
Three approaches were evaluated (Table 10, Onno Paap, 2025; CFIHOS Semantics guide, April 2026):
| Option | Approach | Verdict |
|---|---|---|
| 1 | Separate namespaces for tag and equipment ontologies | Rejected — produces two parallel, disconnected ontologies with redundant class hierarchies. |
| 2 | Single ontology; named graphs for instance-data separation | Partially viable for instance data; does not resolve class-level property restrictions. |
| 3 | Single namespace; separate OWL classes per lifecycle world | Agreed — enables class-level OWL restrictions, SHACL profiles, and explicit lifecycle linking at the class level. |
Agreed solution (Option 3): For each CFIHOS equipment class, two OWL classes are defined in the same namespace, distinguished by a suffix on the CFIHOS ID:
-
cfihos:CFIHOS-3000521T— the tag class (centrifugal pump, specified/functional plant world);rdfs:label "centrifugal pump". -
cfihos:CFIHOS-3000521E— the equipment class (centrifugal pump, actual/physical asset world); same label, distinct IRI.
The two classes carry separate OWL property restrictions: only the properties flagged as tag-relevant are permitted on CFIHOS-3000521T; only equipment-relevant properties on CFIHOS-3000521E. Software vendors endorsed this approach because their tools already maintain separate user interfaces for tag and equipment data, using the same class name with a lifecycle suffix.
The CFIHOS lifecycle overview in Figure 14 shows the three zones — Process (yellow), Process Plant (teal, with TAG circled in red), and Asset (green) — and how PROCESS CLASS, TAG CLASS, and EQUIPMENT CLASS relate to the three-world model. The TAG sits at the boundary between the process plant and asset worlds, connected to both the functional specification and the physical realization.
The Application/Project layer of the IDO architecture (Figure 6) is the level at which these two OWL class variants (-T and -E) appear: both CFIHOS-3000521T and CFIHOS-3000521E are subclasses of API610_OH2_Pump (or equivalent mid-level class), which in turn inherits from the IDO core.
Note
The question of whether CFIHOS-derived classes should inherit from one or two OWL parent classes (single vs. dual parent in IDO) remains open and is tracked in Open issues and pending decisions.
Lifecycle stage grouping for instance data¶
Within each lifecycle world, property values are further grouped by lifecycle stage using the cfihos:hasLifecycleStage relation on each instance individual (Onno Paap, FLUOR Engineering, 2025). A single physical item — for example, the centrifugal pump 11P-101 — is represented by two named individuals in the knowledge graph:
-
ex:2384— typecfihos:CFIHOS-3000521T(tag class), annotatedcfihos:hasLifecycleStage cfihos:TagLifecycleStage. -
ex:4387— typecfihos:CFIHOS-3000521E(equipment class), annotatedcfihos:hasLifecycleStage cfihos:EquipmentLifecycleStage.
The two individuals are linked by cfihos:isFulFilledBy:
cfihos:CFIHOS-3000521T
a owl:Class ;
rdfs:label "centrifugal pump" .
cfihos:CFIHOS-3000521E
a owl:Class ;
rdfs:label "centrifugal pump" .
cfihos:TagLifecycleStage
a owl:Class ;
rdfs:label "tag lifecycle stage" .
cfihos:EquipmentLifecycleStage
a owl:Class ;
rdfs:label "equipment lifecycle stage" .
ex:2384
a owl:NamedIndividual, cfihos:CFIHOS-3000521T ;
cfihos:hasLifecycleStage cfihos:TagLifecycleStage .
ex:4387
a owl:NamedIndividual, cfihos:CFIHOS-3000521E ;
cfihos:hasLifecycleStage cfihos:EquipmentLifecycleStage .
ex:2384 cfihos:isFulFilledBy ex:4387 .
The hasLifecycleStage annotation also extends across the broader set of lifecycle stages recognized by CFIHOS Semantics (Table 11).
| Lifecycle zone | Stages |
|---|---|
| Functional / Tag | FEED (Front-End Engineering and Design), Process Design, Engineering, Procurement, Construction |
| Physical / Equipment | Operations and Maintenance (Assets), Performance (historian data) |
This grouping enables:
-
Querying all properties of a given asset for a specific stage (e.g., retrieve all engineering-phase values for tag
11P-101). -
Comparing values across stages — for example, verifying that the as-built operating pressure is within the design envelope.
-
SHACL validation per stage — shapes can enforce that every
Engineering-stage property datum carries a responsible engineer reference, while everyOperations-stage datum carries a measurement source.
Connection to CQ-4 (Lifecycle context): CQ-4 asks, for a given property value, which lifecycle phase produced it and under what authority. The hasLifecycleStage mechanism at instance level is the direct answer: each property datum individual inherits the lifecycle stage of its bearer individual, enabling phase-aware queries and validations across the full asset lifecycle (see Lifecycle context).
Standards alignment¶
IDO acts as a semantic hub: a shared upper ontology layer that multiple industrial standards can map onto, enabling cross-standard data integration without requiring direct standard-to-standard translations.
As Figure 15 shows, IDO is connected bidirectionally to ISO 10303 (AP 239 and AP 242), CFIHOS, and DEXPI. Each standard maps its classes and properties onto IDO concepts; the IDO layer then enables cross-standard queries and validations. The following subsections document the alignment of DEXPI, CFIHOS, STEP, and IMF with the framework.
Alignment with DEXPI¶
DEXPI (Data Exchange in the Process Industry) defines standardized formats for exchanging P&ID (Piping and Instrumentation Diagram) data and process flow data across the process plant lifecycle. The DEXPI initiative covers:
-
DEXPI Plant — plant structure and topology, centered on the P&ID as a machine-readable information model. Plant items (apparatus, piping, instrumentation) with their connections and a limited set of engineering properties (design pressure, design temperature, material, nozzle data).
-
DEXPI Process — block flow and process flow diagrams: unit operations, streams, instrumentation activities.
DEXPI 2.0 (released 2025) covers both specifications. Properties in DEXPI Plant are a deliberately small set — design pressures, design temperatures, required services, design sizes. DEXPI uses ISO 15926 Part 4 as its reference data library for class and property definitions; additional concepts are published in the DEXPI sandbox.
DEXPI lifecycle zones and the three-world model¶
DEXPI organizes lifecycle information around three principal information structures, color-coded in its documentation:
The four zones in Figure 16 and Table 12 correspond directly to the three-world model (The three-world model):
| DEXPI zone (color) | Three-world equivalent | Typical content |
|---|---|---|
| Process (orange) | Process world | Process, ProcessStep, UnitOperation (e.g., Pumping), Stream, MaterialPort |
| Specified process plant (blue/green) | Specified (planned) plant | ProcessPlant, PumpSystem, Pump, CentrifugalPump, PipingNetworkSystem — functional and technical design; P&ID |
| Assets / actual plant (purple) | Actual (realized) asset | Purchased and installed physical objects with serial numbers and asset register entries; maintenance data |
| Vendor product model (pale blue) | (no direct IDO equivalent; non-actual physical objects in a model catalog) | Device types offered by manufacturers; product catalog data |
The bridging relations between DEXPI zones map onto IDO object properties:
-
Process ↔ Specified plant:
lis:hasParticipant/lis:participatesIn— a specified plant object (e.g.,Pump P0001) participates in a process activity (e.g.,Pumping UO002). -
Specified plant ↔ Actual plant:
lis:implements/lis:implementedBy— an actualCentrifugalPump(asset, equipment number12345) implements the specifiedPump P0001.
DEXPI property model and IDO alignment¶
DEXPI properties are typed with quantity kinds from ISO 15926 Part 4 and units from QUDT. The IDO-DEXPI alignment maps each DEXPI property attribute to the IDO property pattern, illustrated here for DifferentialPressure on specified_Pump.
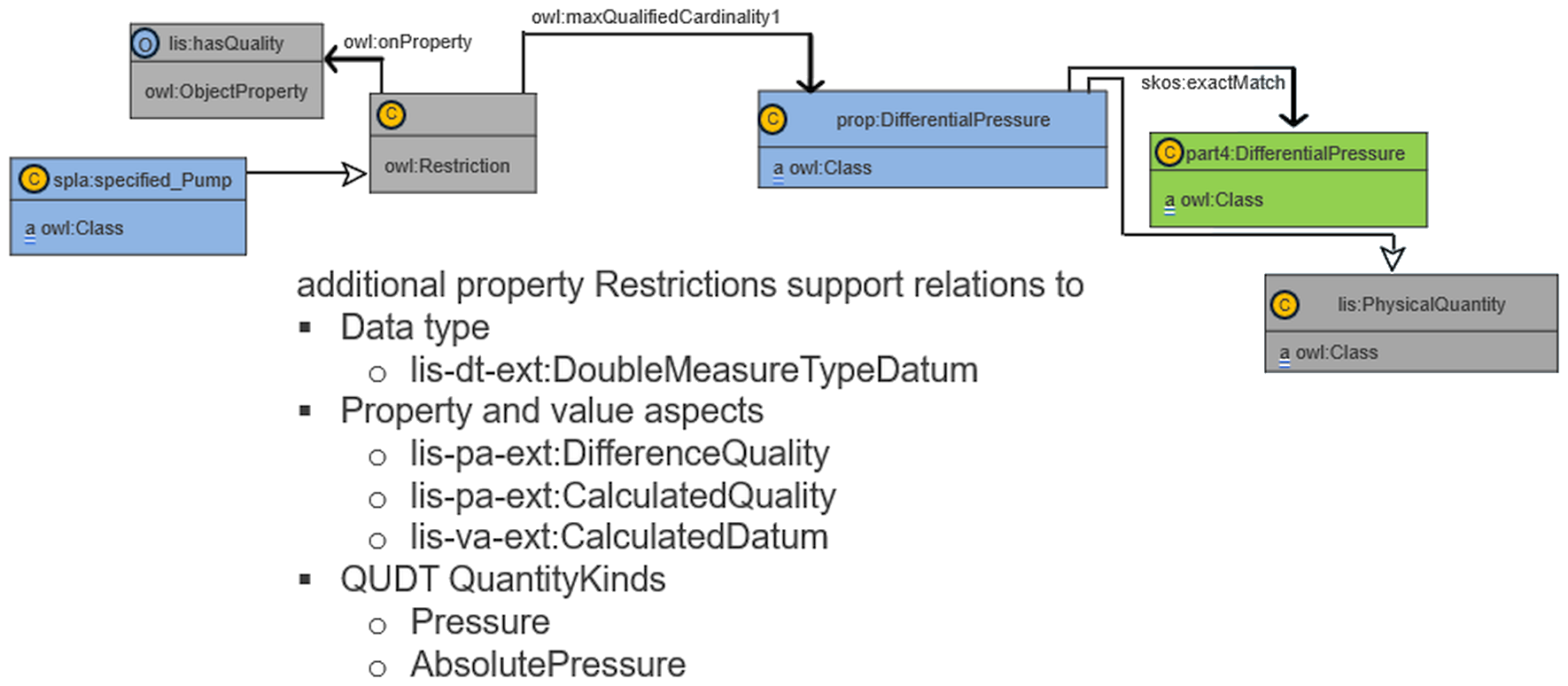
Figure 17 shows the class-level pattern. The property DifferentialPressure is defined as a dependent class and as a subclass of lis:PhysicalQuantity. It is assigned as permissible property of the class specified_Pump. Using an OWL restriction, the QUDT QuantityKind Pressure is assigned. The relations to the data type DoubleMeasureTypeDatum, the QUDT QuantityKind AbsolutePressure, and the property and value aspects DifferenceQuality, CalculatedQuality, and CalculatedDatum are supported with Restrictions (see Figure 17).
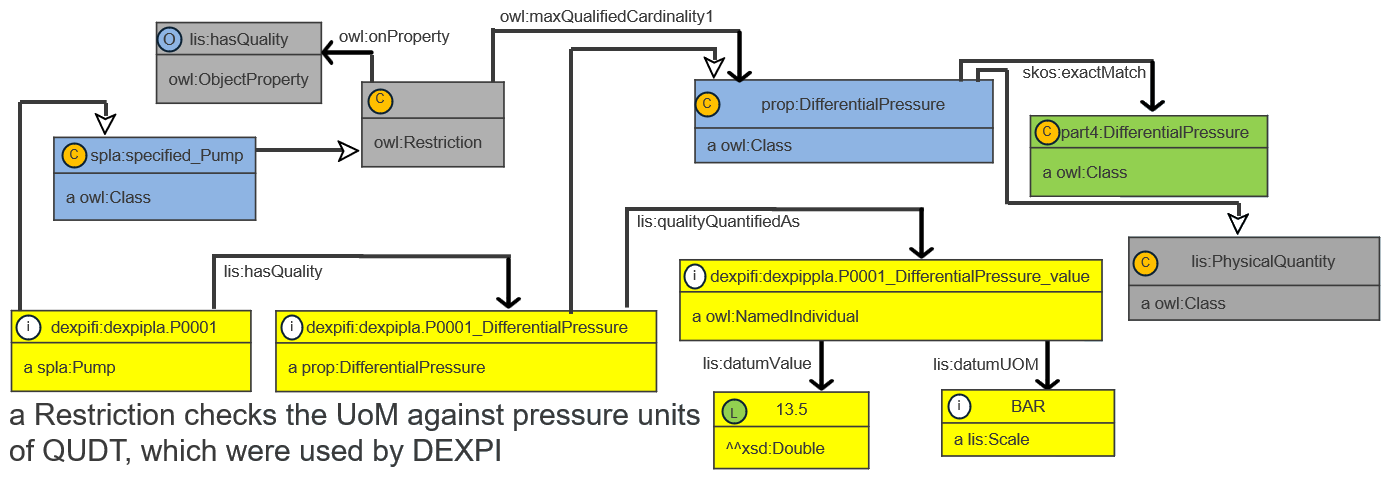
At the instance level (Figure 18), lis:hasQuality and lis:qualityQuantifiedAs are used to connect the typical IDO instance triple parts: bearer, property and value. The unit of measurement BAR as a unit of QUDT is used. This pattern is consistent with the IDO property reification model (Unified property reification model): the lis:Quality instance is the reified property node; lis:qualityQuantifiedAs links it to the datum; the datum carries the numeric value and QUDT unit.
Knowledge graph results¶
The pump lifecycle use case was fully implemented in Turtle and verified in GraphDB. Figure 19 shows the knowledge graph connecting process objects to specified plant objects; Figure 20 shows the connection from specified to actual plant objects.
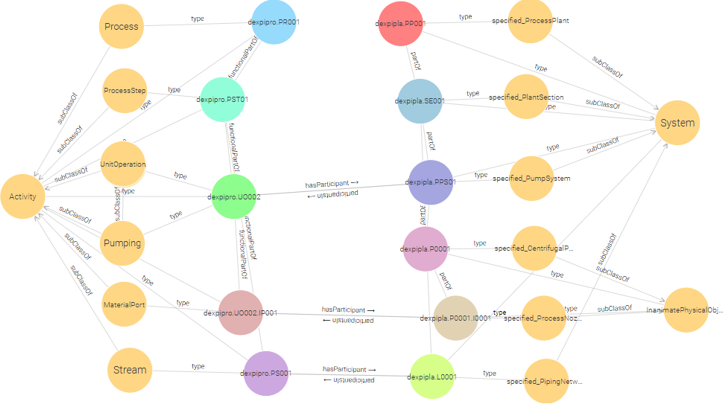
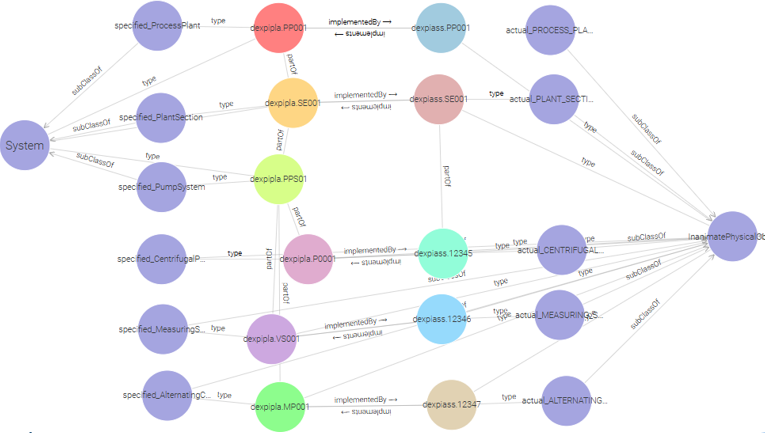
In Figure 19, dexpipro.UO002 (Pumping, a lis:Activity subtype) is connected via lis:hasParticipant to dexpipla.P0001 (the specified pump in the plant zone). In Figure 20, dexpipla.P0001 is connected via lis:implementedBy to dexpiass.12345 (the actual centrifugal pump with serial number 47110), which is typed as actual_CentrifugalPump.
Modeling gaps and extensions¶
The DEXPI alignment work identified several gaps in the base IDO vocabulary (Heiner Temmen, DEXPI e.V., May 2026):
-
Specified vs. actual distinction:
lis:InanimatePhysicalObjectdoes not distinguish between specified and actual physical objects. The use case introducesspecified_andactual_prefixed subclasses (e.g.,spla:specified_Pump,pequi:actual_CentrifugalPump) in a domain-level ontology layer below IDO. -
IDO PLM modules not used: The IDO PLM modules for Process and Equipment are incomplete and not actively maintained. ISO 15926 Part 4 was used as the reference data library instead; QUDT for units.
-
Internal functional/physical bridge: Within the specified plant, functional objects (e.g.,
PumpSystem) and physical/technical objects (e.g.,CentrifugalPump) require an additional propertylis-ext:specifiedTechnicalBynot present in base IDO.
These gaps are candidates for future IDO extensions and are noted in Open issues and pending decisions.
Standards interoperability context¶
DEXPI and CFIHOS have a formal Memorandum of Understanding for data alignment. The IDO-based framework provides the shared semantic reference layer that makes this alignment computable: a property defined in DEXPI maps to the same IDO quality pattern as the corresponding CFIHOS property, so the two can be compared and merged without manual re-mapping. The same principle extends to ISO 10303 AP 239/242 (see Alignment with ISO 10303 (STEP)).
The full worked example — Turtle files, SHACL shapes, and XML source — is documented in Pump Lifecycle Use Case.
Alignment with CFIHOS¶
CFIHOS (Capital Facilities Information Handover Specification), managed as IOGP JIP-36, defines standardized information requirements for data handover between operators, EPC contractors, and suppliers in capital projects across the process and energy sectors. Its Reference Data Library (RDL) forms the core of the standard: it contains more than 10,000 property definitions, equipment classes, document types, and discipline codes, originally assembled from JIP33 equipment data sheets specifying exactly which properties apply to which equipment classes. Version 2.0 (October 2024) restructured the specification as a formal requirements document (REQIF-compatible, with CFIHOS-SP-TR-XXX identifiers per requirement) and introduced several significant additions:
-
Core vs. Extended RDL split — enables phased adoption; implementers can conform to Core without taking on the full property set.
-
Greenhouse Gas emissions properties — new properties, units, and document references for Scope 1, 2, and 3 GHG emission calculations.
-
Energistics alignment — unit-of-measure harmonization with the Energistics WITSML/PRODML family.
-
ISO 14224 integration — reliability and maintenance properties for operational lifecycle.
-
REQIF neutral file format — machine-readable requirements file alongside the normative document for requirements-management tool integration.
The CFIHOS Semantics Group¶
The CFIHOS Semantics Working Group was established in 2024 within the CFIHOS governance structure (IOGP JIP-36) with the mandate to develop IDO-compliant semantic representations of CFIHOS data. The work is led by Onno Paap (FLUOR Engineering) and operates within the IOGP Steering Committee framework alongside the RDL Group, Data Model Group, and Implementation Group. The CFIHOS Semantics project contributes to and draws from the alignment work documented in this Handbook.
Formal Memoranda of Understanding are in place between CFIHOS and the following organizations to ensure property alignment across standards: DEXPI e.V., PCA (POSCCAESAR), CII (Construction Industry Institute), and Energistics. The DEXPI–CFIHOS MOU in particular targets joint alignment on lifecycle stage modeling and property definitions for process-plant equipment (see Alignment with DEXPI).
Alignment approach¶
In the CFIHOS relational model, class-to-property bindings are held in a single table (tag_or_equipment_class_property) with boolean flags indicating whether each property applies to the tag context, the equipment context, or both. This flat table structure does not enforce the tag/equipment distinction at the schema level. The IDO-based semantic representation (Table 13) makes this distinction explicit through separate OWL class definitions and owl:allValuesFrom restrictions (see Tag and equipment class distinction).
| CFIHOS element | IDO-based representation |
|---|---|
| Equipment and tag classes (RDL) | IDO bearer classes, declared as subclasses of lis:InanimatePhysicalObject and lis:PhysicalArtefact |
tag_or_equipment_class_property table |
Separate CFIHOS-xxxxxxT (tag) and CFIHOS-xxxxxxE (equipment) OWL classes, each with its own owl:allValuesFrom restrictions (see Tag and equipment class distinction) |
| Property definitions (name, data type, unit, allowed values) | Knowledge-ontology property classes with lis:hasQuality / lis:qualityQuantifiedAs chains and typed datum individuals |
| JIP33 property sets (industry-agreed subsets) | Class property profiles composed of owl:allValuesFrom restrictions and SHACL shapes |
| Assigned properties (tag name, manufacturer) | cfihos:hasAssigned → cfihos:AssignedProperty individuals with cfihos:NonTranslatableStringTypeDatum or cfihos:ObjectReferenceTypeDatum |
Scale and pragmatism¶
CFIHOS contains more than 10,000 properties; JIP33 contributes a further \~11,000 properties that the CFIHOS Semantics Group is mapping into the RDL. Full reification for every property is not always necessary or practical. This framework addresses the scale challenge through two mechanisms:
-
Shortcut properties (see Unified property reification model): simplified
owl:DatatypePropertyassertions that are explicitly traceable to the full reified model, allowing tools that cannot process reified triples to still consume property values. -
Conformance levels (see Conformance levels): a phased adoption path from basic identification through fully grounded semantic descriptions, so organizations can implement incrementally without losing compatibility.
The CFIHOS Semantics approach also reduces the effective number of property classes through the PropertyAspect mechanism: instead of separate named classes for "design pressure", "operating pressure", and "maximum allowable pressure", a single pressure class is combined with a ScopeAspect or RangeAspect individual (see Property aspects). This is projected to reduce the JIP33 mapping effort significantly by identifying scope-qualified variants of the same underlying quantity kind.
Tooling¶
The open-source Sous-le-Sens tool (sponsored by TotalEnergies, hosted by the Knowledge Graph Alliance platform) supports ontology authoring, graph visualization, and SPARQL querying for CFIHOS-IDO aligned knowledge graphs. It provides a web-based interface (Weaver for visualization, Onto Creator for authoring) and exports Turtle files compatible with any OWL 2 triple store.
A Python automation pipeline that reads the CFIHOS RDL Excel files and generates Turtle class and restriction definitions programmatically is under development by the CFIHOS Semantics Group. Once complete, it will allow the full CFIHOS RDL to be published as a queryable SPARQL endpoint with a graphical navigation interface.
Note
Detailed property instance models --- including Turtle for dependent quantifiable properties, OWL class restrictions, assigned tag name, and manufacturer reference --- are in CFIHOS Semantics Use Case.
Alignment with ISO 10303 (STEP)¶
ISO 10303 (STEP — Standard for the Exchange of Product model data) is the primary international standard for the computer-interpretable representation and exchange of product manufacturing information. Mainly through Application Protocol 242 (AP 242, multi-discipline 3D engineering), AP 239 (PLCS, product lifecycle support), and the harmonized STEP Core model, STEP covers the full industrial lifecycle — from design through manufacturing, configuration management, and long-term archiving — across aerospace, automotive, shipbuilding, and process industries. ISO/TC 184/SC 4, which maintains STEP, is also the committee responsible for IDO (ISO 23726-3) and ISO 15926, giving this family of standards a shared governance context.
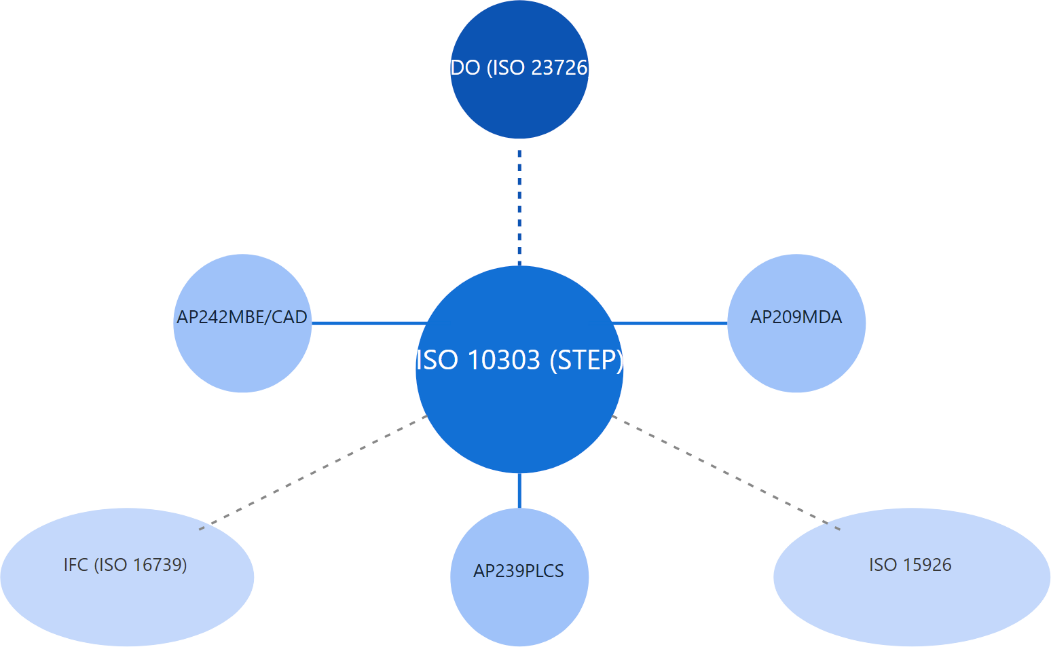
The EXPRESS-to-OWL translation challenge¶
STEP’s traditional modeling language is EXPRESS, a formal schema language developed by SC 4 in 1984 when no established modeling languages existed. EXPRESS schemas are not directly compatible with OWL 2 DL: they carry engineering semantics and support constructs (particularly SELECT types — named choices between two or more types) that have no direct OWL counterpart. The modernized STEP architecture uses SysML v1 as its modeling notation and XMI (XML Metadata Interchange) for serialization of the STEP Core model. XMI is a deterministic, parser-friendly format with stable element identifiers, making it a well-suited starting point for rule-driven transformation to OWL.
Within the Arrowhead fPVN project, Torbjörn Holm developed an automated transformation pipeline: SysML XMI → OWL 2 DL, mapping SysML class constructs to OWL classes, SELECT types to owl:unionOf union classes, and STEP properties to OWL object and data properties. The pipeline was first validated as a semi-manual proof of concept, then fully automated using a Python tool. The resulting ontology contains 12,610 axioms, 1,075 classes, 2,113 object properties, and 3,374 subclass relationships, and was presented to SC 4 in Nagasaki in October 2025.

Integration pattern¶
The STEP Core OWL ontology operates as a Data Model Ontology (see Data model ontology) in the IDO framework. Alignment mappings — declaring STEP product-structure classes as subclasses of IDO bearer classes (lis:InanimatePhysicalObject, lis:PhysicalArtefact) — then lift STEP product data to the IDO Integration Ontology layer, making it query-compatible with DEXPI, CFIHOS, and ISO 15926 knowledge graphs within the same semantic architecture.
The key architectural insight is that full cross-standard alignment does not require mapping every class. In the Arrowhead fPVN project’s Use Case 2.9 (Digital Twin), only a small number of STEP and DEXPI classes were aligned with IDO, yet the interoperability already produced measurable business benefits. Benefits grow incrementally as more classes are aligned over time.
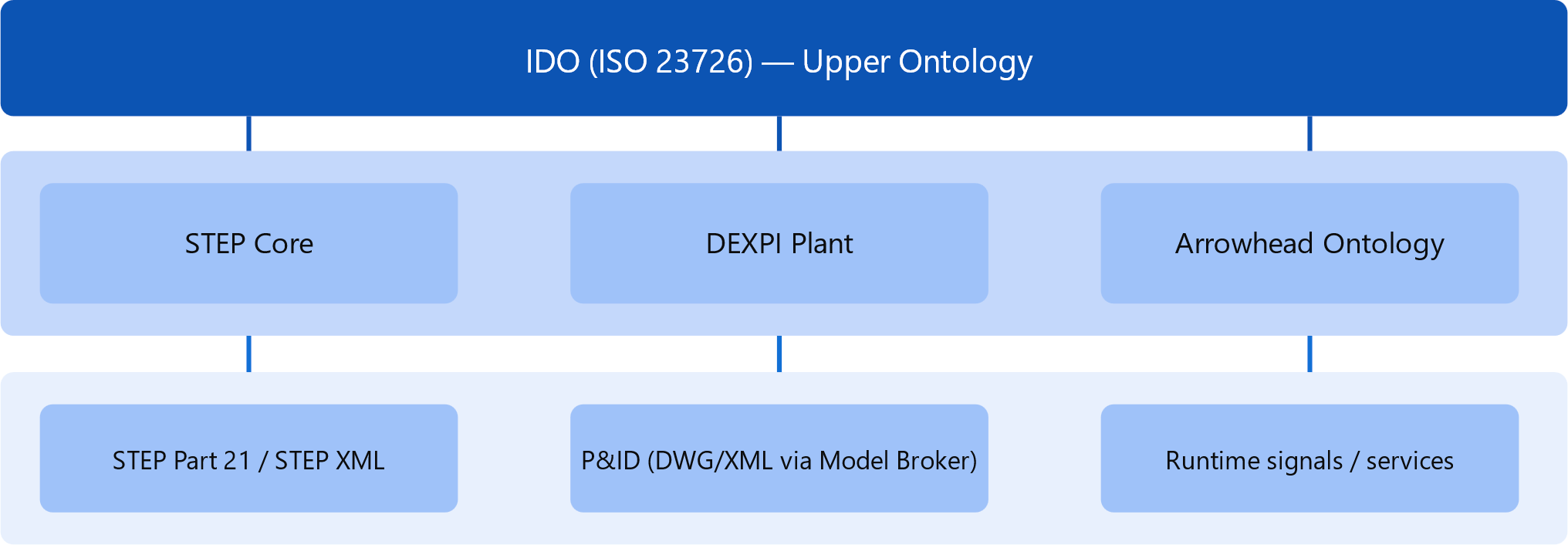
Scope and geometry exclusion¶
STEP alignment within this framework focuses on product property description (PDM schema modules: activity, analysis, breakdown, document management, configuration, PDM) and product lifecycle support (AP 239 PLCS). Geometry and CAD-specific representations (solid models, tessellations, B-rep surfaces) are out of scope: they require specialised STEP exchange formats and are not consumed by the IDO property layer.
Further work, coordinated with SC 4, is planned to formalize transformation rules as ISO Technical Specifications and to position IDO as the reference framework for shared semantics across ISO 10303, ISO 15926, DEXPI, IFC, and other industrial standards.

Alignment with ISO 15926¶
ISO 15926 is a family of standards for the integration of lifecycle data for process plants and oil & gas production facilities. It is one of the most mature and semantically comprehensive industrial data standards, covering product design, engineering, manufacturing, operation, and maintenance. ISO 15926 was developed jointly by EPISTLE (European process industry) and PCA (POSC Caesar Association, combining the Petrotechnical Open Software Corporation and the Norwegian Caesar Offshore initiative), resulting in the foundational ISO 15926-2:2003 data model.
The parts of ISO 15926 most relevant to this framework are:
-
ISO 15926-1:2004 — Overview and fundamental principles
-
ISO 15926-2:2003 — The upper ontology data model
-
ISO/TS 15926-4 Ed. 4 — Core reference data (the Reference Data Library)
-
ISO 15926-6:2024 — Methodology for developing and validating reference data
Relationship to IDO¶
Both ISO 15926-2:2003 and ISO 23726-3 (IDO) are upper ontologies that deliberately exclude domain-specific data. Their alignment is achieved by a subclass pattern: classes in ISO 15926-4 are declared subclasses of their corresponding IDO classes. This makes ISO 15926 reference data directly accessible through IDO-based queries and reasoning, without modifying the normative content of either standard.
The ISO 15926-2 data model uses entity data types organized in a universal subtype/supertype hierarchy. ISO 15926 was not originally designed for reasoning, but ISO 15926-4 Ed. 4, when published as OWL, provides a basis for OWL 2 DL inference. The PCA Reference Data Library (PCA RDL) extends ISO 15926-4 with production-specific reference data, and the alignment work in Arrowhead fPVN extended this further to cover pulp and paper industry concepts — demonstrating that the framework is not O&G-specific but applicable across process plant industries.
Reference data categories¶
ISO 15926 reference data is organized in a hierarchy of categories (ISO 15926-1:2004):
At the Core Class level, there is considerable overlap between O&G and pulp & paper industries, reflecting their shared process plant character. At the Standard Class level, divergence emerges: O&G predominantly aligns with US standards, while European pulp & paper relies on EN and ISO standards, with IEC classes shared across both. IDO alignment is straightforward at the Core Class level and integrates seamlessly with the multi-standard knowledge graph architecture also used for STEP, DEXPI, and CFIHOS.
The PCA RDL and multi-industry scope¶
The PCA RDL provides over 10,000 reference data instances built on ISO 15926-4, including lifecycle stages, functional object classes, and quantity kinds. Several of these are referenced by IDO patterns in this framework — for example, the lifecycle stage identifiers used in the pump lifecycle use case originate from the PCA RDL namespace (http://rds.posccaesar.org/ontology/lis14/rdl/). Future work will formally publish the Arrowhead fPVN reference data extensions as a contribution to ISO 15926-4 Ed. 5.
The PCA PLM Ontology and property aspect vocabulary¶
Distinct from the ISO 15926-4-based Reference Data Library, PCA also maintained a PLM (Product Lifecycle Management) Ontology providing a vocabulary for specifying the context of property values — in particular the "Datum Type" classification scheme. The PLM Ontology is no longer actively maintained upstream, but its content remains relevant and widely referenced in industrial data modeling practice.
In this project, the Datum Type part of the PLM Ontology has been:
-
Updated to IDO v4.2 (FDIS), replacing ISO 15926-2 type references with the corresponding IDO classes.
-
Split into two modular ontologies, reflecting IDO’s fundamental distinction between a property (
lis:Quality) and its value (lis:QualityDatum):
Quality Property Aspect Extension Ontology (property-side aspects)
: Contains PCA’s original classes that qualify the nature of the property itself, including CalculatedQuality, DesignQuality, ProvenanceQuality, and ScopeQuality.
Quality-Datum Value Aspect Extension Ontology (value-side aspects)
: Contains PCA’s original classes that qualify the role or position of a specific datum value, including NominalDatum, NormalDatum, and CalculatedDatum, extended with UpperLimit and LowerLimit to cover range constraints not present in the original PCA model.
Note
Some aspect classes --- such as CalculatedDatum and
CalculatedQuality --- appear in both ontologies because the original
PCA model assigned them a dual role (qualifying both the property and
its value). This dual membership is preserved intentionally to maintain
alignment with existing implementations that reference the original PLM
classes.
This approach is intended as a template: the same update-and-split methodology should be applied to the remaining parts of the PLM Ontology as future work.
Alignment with IEC 61360-1:2017¶
IEC 61360-1:2017 (Standard representation of product properties and their values — Part 1: Principles and methods) defines the conceptual structure for representing properties, data types, and value domains in industrial product data. It is the normative basis for eCl@ss, the IEC Common Data Dictionary (CDD), and the ECLASS RDF serialization. DEXPI also draws on IEC 61360-1 data-type concepts for its core data types. The standard is most directly relevant to this framework in two areas:
Data types: IEC 61360-1 defines a set of data types for representing property values, including measure types (real, integer, rational), string types, boolean, and complex types.
Value levels (LEVEL_TYPE): IEC 61360-1 specifies four named value roles — MIN, NOM (nominal), TYP (typical), and MAX — that qualify the position of a value within a range or specification band.
Project extension ontologies derived from IEC 61360-1¶
Two extension ontologies were developed in this project to represent IEC 61360-1 concepts in IDO-aligned OWL:
Quality-Datum Data Type Extension Ontology
: Implements data types for lis:QualityDatum in accordance with IEC 61360-1’s data-type classification. Defines named subclasses of lis:QualityDatum — including DoubleMeasureTypeDatum, IntegerMeasureTypeDatum, and RationalMeasureTypeDatum — to enable type-safe validation and interoperability with eCl@ss and DEXPI systems that already implement IEC 61360-1 types. This ontology was originally developed by Siemens AG and is reused here with stated IDO alignment.
Quality-Datum Value Aspect Extension Ontology
: Aligns with IEC 61360-1’s LEVEL_TYPE concept and makes each level role a separate OWL class. This approach enables precise semantic composition: a datum individual can simultaneously bear a Range aspect (e.g., UpperLimit, LowerLimit from the PCA PLM extension — see The PCA PLM Ontology and property aspect vocabulary) and a value-level aspect (e.g., NominalLevel, MaximumLevel) without combining them into a single flat class. All four IEC 61360-1 levels are supported, and the representation is extensible.
Only a subset of IEC 61360-1 has been covered so far. Further data types and value aspects will be incorporated as additional extension modules following the same pattern. For full detail, see Data Type and Value Representation Pattern.
IDO as a unifying language¶
Having established three levels of expressiveness, we now look more closely at the highest level. This will be done from the perspective of engineering experts whose knowledge should be made both human-readable and machine-readable — and through this, interoperable.
Such engineering experts already use existing standards like ECLASS or IEC CDD, which are both based on IEC 61360-1:2017. One task of such experts is to ensure that international standards are mapped to the data used in their company in order to enable trustworthy communication with internal and external partners who use the same standard. This includes the mapping between different standards.
Standards usually focus on a specific perspective in order to reduce complexity. In the end, all perspectives belong together. Achieving this efficiently is a challenge for engineers. The thesis is that IDO has the essential language elements to depict information coherently from different perspectives. If this thesis is proven, IDO would be a candidate as the core of knowledge governance and could be the enabler for a seamless value chain from the customer to the solution provider to the sub-suppliers and back. It is therefore of interest to develop initial ideas to answer the following questions:
-
How does the language defined in IEC 61360-1:2017 match with the language defined in IDO?
-
Which elements overlap?
-
Which elements differ and how could they be merged to collect all information in one place?
Initial ideas for answering these questions are developed step by step below. These ideas are intended to encourage the definition of uniform rules for the application of IDO, incorporating existing standards and with this enabling wide-ranging interoperability.
Classes and Properties in IEC 61360-1:2017¶
To answer these questions step by step, the main elements from IEC 61360-1:2017 will be compared with those from IDO. The main elements defined in IEC 61360-1:2017 are:
-
iec61360:Item_class, -
iec61360:Property, -
iec61360:Unit_of_measure, -
iec61360:Value_list, -
iec61360:Value, -
iec61360:Relation -
and as root element
iec61360:Dictionary_element
As shown in Figure 27 of IEC 61360-1:2017. The prefix iec61360: is not defined in IEC 61360-1:2017. It is introduced here to clearly assign elements to the standards in which they are defined.
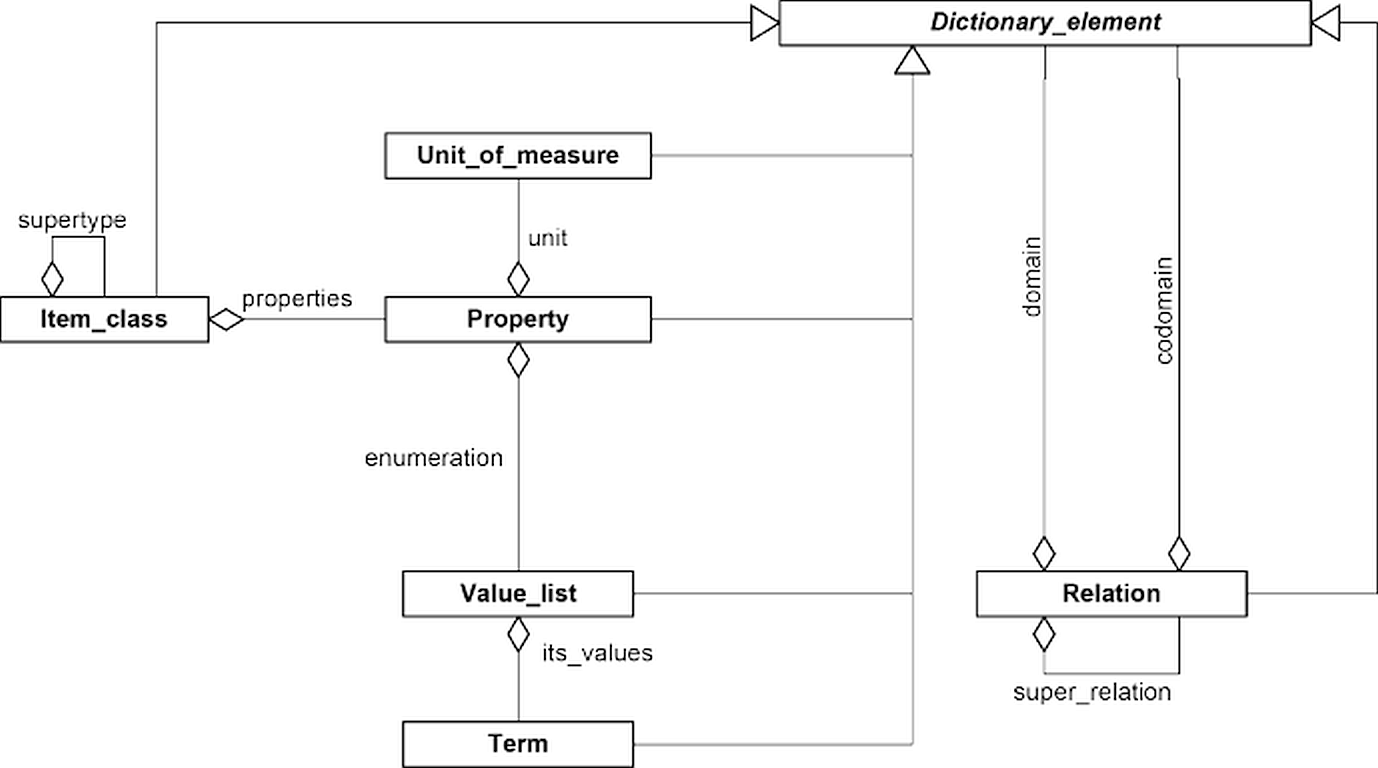
In addition, two general terms are introduced: Class and Property. Class is used in this concept as it is defined in OWL Web Ontology Language Reference, Chapter 3. Classes: Classes provide an abstraction mechanism for grouping resources with similar characteristics. Like RDF classes, every OWL class is associated with a set of individuals, called the class extension. The individuals in the class extension are called the instances of the class. A class has an intentional meaning (the underlying concept) which is related but not equal to its class extension. Thus, two classes may have the same class extension, but still be different classes. The similar term of Class in IEC 61360-1:2017 would be entity (and not class): 3.1.12 entity: class of information defined by common properties. (3.1.6 class: abstraction of a set of similar products.)
Property is used in this concept as it is defined in IEC 61360-1:2017, Chapter 6.2: information object that characterizes the Item_class(es) to which it is associated. A property, when used, always has an associated value, such as a numerical value together with a unit, or a qualitative value taken from a predefined list. It should be noted that Property is not used as a generic term for owl:AnnotationProperty, owl:ObjectProperty or owl:DatatypeProperty. It is viewed from the perspective of an engineer who wants to use IDO. The term PROPERTY as defined in IEC 61360-1:2017 is more common for engineers.
Classes and Properties in ISO/DIS 23726-3 IDO¶
The most important elements defined by IDO to be mapped to the elements defined in IEC 61360-1:2017 are shown in the following list. The elements which are relevant for the mapping to IEC 61360-1:2017 are highlighted in bold font. The prefix lis: is used for the elements defined in IDO. The indentations in the following list symbolize the parent-child relationship between the elements. The inverse owl:ObjectProperties are not listed.
-
owl:Class -
lis:Object-
lis:InformationObject -
lis:QualityDatum -
lis:UnitOfMeasure
-
-
lis:Dependentlis:Quality
-
owl:ObjectProperty -
lis:hasPart-
lis:hasContentPart -
lis:datumUOM
-
-
lis:hasQuality -
lis:representedInlis:qualityQuantifiedAs
-
owl:DatatypeProperty -
lis:datumValue
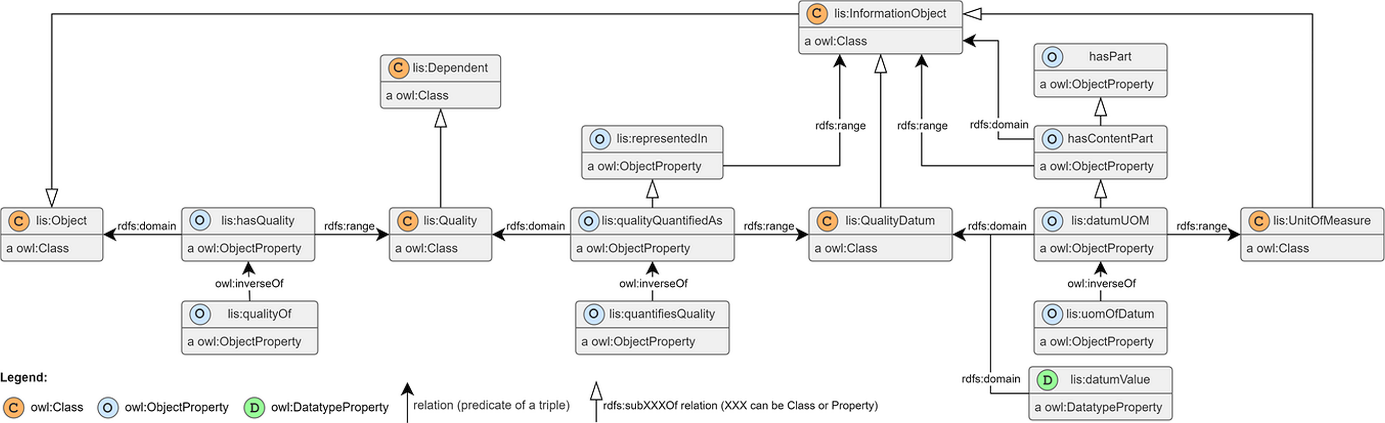
Figure 28 shows the elements which are relevant for the mapping to IEC 61360-1:2017 graphically together with the parent elements. The picture shows that IDO expresses the relationship between an object and its properties (here lis:Quality) with semantic precision. Expressed in words, the image shows the following:
-
A
lis:Objectcan havelis:Quality. -
lis:Qualityis a subclass oflis:Dependent.lis:Dependentis defined as "An entity that is an inherent quality or realizable potential of an object". This means that a usedlis:Qualityalways needs a bearer which is alis:Object. -
The relationship between
lis:Objectandlis:Qualityis defined aslis:hasQuality. -
The relationship between
lis:Qualityandlis:Objectis defined aslis:qualityOf. -
Not shown in the picture, but defined in IDO, is that
lis:Objectandlis:Dependentare disjoint classes. This means thatlis:Objectandlis:Qualityare also disjoint. -
A
lis:Qualitycan havelis:QualityDatum. -
lis:QualityDatumis a subclass oflis:InformationObjectwhich is a subclass oflis:Object. -
The relationship between
lis:Qualityandlis:QualityDatumis defined aslis:qualityQuantifiedAs. -
lis:qualityQuantifiedAsis a subPropertyOflis:representedInwhich is defined as a relation pointing to alis:InformationObject. -
The relationship between
lis:QualityDatumandlis:Qualityis defined aslis:quantifiesQuality. -
A
lis:QualityDatumcan havelis:UnitOfMeasureandlis:datumValue. -
lis:UnitOfMeasureis a subclass oflis:InformationObjectwhich is a subclass oflis:Object. -
The relationship between
lis:QualityDatumandlis:UnitOfMeasureis defined aslis:datumUOM. -
lis:datumUOMis a subPropertyOflis:hasContentPartwhich is defined as a relation betweenlis:InformationObject. -
lis:hasContentPartis a subPropertyOflis:hasPart. -
The relationship between
lis:UnitOfMeasureandlis:QualityDatumis defined aslis:uomOfDatum.
All this information is human- and machine-readable (which is the nature of the semantic web standards defined by the World Wide Web Consortium W3C, on which IDO is based). Table 14 offers a mapping of the elements defined in IDO and elements defined in IEC 61360-1:2017. IDO uses the following OWL-defined elements as upper elements analogous to iec61360:Dictionary_element in IEC 61360-1:2017:
-
owl:Thingforowl:Classes -
owl:topObjectPropertyforowl:ObjectProperties -
owl:topDataPropertyforowl:DatatypeProperties
Table 15 shows an initial indicator for the thesis that IDO provides a unifying language together with the existing semantic web standards defined by W3C. It has been shown that there are differences in the precision of the elements defined in IDO and IEC 61360-1:2017. It therefore seems possible to use IDO as a higher-level language for integrating standards. If this were the case, it would reduce the effort that engineers currently have to put into mapping properties from different standards. It is therefore worth delving deeper into the details. The following table shows some points which are needed to set up a framework to enable property mapping holistically. The core idea is: IDO makes it possible to create a place where information from different standards is brought together.
| Element in IDO | Element in IEC 61360-1 | Comment |
|---|---|---|
|
|
Deeper comparison will come later |
|
|
IDO is more precise than IEC 61360-1:2017 |
|
|
|
|
|
similar |
|
|
IDO is more precise than IEC 61360-1:2017 |
|
|
|
|
|
|
|
— |
|
— |
|
Several concepts are defined in the W3C standards to define value lists. Therefore, no definition in IDO is needed |
— |
|
| Aspect | Available | To be discussed and introduced |
|---|---|---|
Language |
IDO: Basic elements to define Properties precisely. IEC 61360-1:2017: Additional elements for more details |
|
Knowledge/ |
Use case to map Properties from different standards |
|
Knowledge-Driven Data |
— |
Infrastructure to support the integration of international Standards which are defining Properties. This should include:
|
Alignment with IMF¶
The Information Modelling Framework (IMF), developed within the READI Joint Industry Project (JIP) by TechnipFMC and partners, targets the same underlying problem as this framework: the fragmentation of engineering and asset information across document-centric workflows. IMF is grounded in ISO/IEC 81346 (Reference Designation System) and relies on W3C semantic technologies (RDF, OWL, SHACL) as its implementation layer — a direct point of contact with the IDO-based approach documented here.
The three-pillar architecture¶
IMF rests on three pillars:
Specification Model
: Built by engineers using the ISO/IEC 81346 reference designation system. Organizes information according to three aspects: Functional (=, what the system does), Physical/Product (-, what it is made of), and Locational (+, where it is located), with a fourth Installed aspect (::) for as-built documentation. This is where domain knowledge is captured formally.
Asset Model
: The ontology domain layer, expressed in RDF/OWL/SHACL. Acts as the semantic integration point between the Specification Model and the Application Model. Operates "under the hood" — engineers use the Specification Model, while the Asset Model provides machine-interpretable semantics.
Application Model
: The IT and digital domain: legacy systems (SAP, engineering databases, datasheets), connected through International Resource Identifiers (IRIs) based on the ISO/IEC 81346 RDS codes.
Three fundamental relations structure the model: partOf (hierarchical breakdown within an aspect), connectedTo (topological connectivity and medium flow), and fulfills (requirement–solution threading across aspect boundaries).
Alignment with the three-world model¶
IMF’s Functional aspect corresponds to the process (Process world and functional entity) in the three-world model described in this Handbook (see The three-world model). IMF’s Physical/Product aspect corresponds to the specified plant. IMF’s Locational aspect adds a spatial dimension compatible with IDO’s lis:SpatialLocation hierarchy. The fulfills relation in IMF maps to lis:implements / lis:implementedBy in IDO.
Disposition-parthood and property propagation¶
Nils Sandsmark (2024) identifies a specific challenge at the intersection of IMF and IDO: IMF’s functional hierarchy implies disposition parthood — where a functional component inherits qualities (dispositions) from its parent system. This has implications for how property aspects (see Property aspects) are modeled in IMF-based structures: a quality defined at the system level propagates automatically to subsystems through the partOf hierarchy. The IDO lis:hasPart property combined with quality inheritance patterns can accommodate this, though formal axioms for this propagation pattern remain an open item in IDO.
Status and further work¶
IMF was studied in Arrowhead fPVN but not incorporated as a validated work item; active cooperation paused in spring 2025. Conceptually, IMF and the IDO-based approach are complementary rather than competing: IMF provides an engineering-facing modeling language for subject matter experts, while IDO provides formal ontological foundations for semantic interoperability across standards. IMF’s classifier references to external reference data libraries are an explicit integration point: IDO-aligned ontologies could serve as those reference libraries, grounding IMF models formally without requiring changes to the IMF language. Future work should explore this integration in pilot scenarios and consider contributions back to the READI JIP and relevant ISO standardization activities.
Alignment with AFO¶
The Arrowhead Framework Ontology (AFO) is a formal OWL 2 ontology developed within the Arrowhead fPVN project by Oskar Wintercorn and Jan van Deventer (Luleå University of Technology). Unlike the engineering lifecycle standards covered in the preceding sections, the AFO operates at the operational layer: its purpose is to represent the current runtime deployment state of an Arrowhead framework local cloud as a machine-queryable knowledge graph.
Scope¶
AFO models local clouds, systems, husks, unit assets, hosts, servers, provided services, consumed services, and core-system roles (Service Registrar, Orchestrator, Certificate Authority). Subclasses such as afo:ResilientLocalCloud and afo:SecureLocalCloud are defined through OWL axioms, enabling automated classification of deployment status through reasoning rather than manual inspection.
AFO is not a formal ISO standard but is accompanied by SHACL shapes for structural validation and by the KGrapher system, which automatically extracts runtime deployment snapshots from live Arrowhead deployments into timestamped RDF named graphs stored in a triple store.
Integration with IDO and the semantic stack¶
Initial IDO alignment work has been carried out, positioning AFO concepts as subclasses of IDO bearer and functional classes. This places the AFO within the same semantic architecture as STEP, DEXPI, and CFIHOS: each standard provides a domain-specific knowledge graph layer, with IDO serving as the shared upper ontology that enables cross-layer queries.
In Use Case 2.9 (Digital Twin), AFO served as the semantic foundation for the runtime deployment layer, with SPARQL queries answering competency questions about service dependencies, deployment health, and temporal history. The digital thread capability — reconstructing the history of a physical sensor at a functional location across timestamped deployment snapshots — demonstrates how the operational AFO layer connects to the engineering lifecycle layer represented by DEXPI and CFIHOS.
Security considerations¶
Because deployment knowledge graphs make topology and service dependencies machine-readable, they expose operationally sensitive information. Production deployments must include strong authentication, authorization, and network segmentation around the knowledge graph repository and its SPARQL endpoints. Filtered views and access-controlled interfaces are prerequisites for broader industrial adoption where organizational boundaries are crossed.
Open issues and pending decisions¶
This section collects modeling decisions and open questions identified during the development of this Handbook that require resolution by the IDO core team, the CFIHOS Semantics Group, the DEXPI working group, or other relevant bodies (Table 16). Each entry is tagged with an identifier (OI-xx) that can be referenced from the body of the document.
| ID | Topic | Description |
|---|---|---|
| OI-01 | Intrinsic / assigned terminology | The distinction between intrinsic and assigned properties (Intrinsic and assigned properties) has not yet been formally reviewed by the IDO core team and may require alignment with future IDO releases. The terminology is used consistently throughout this Handbook pending that review. |
| OI-02 | lis:DoubleMeasureTypeDatum for quantifiable properties |
The DEXPI property modeling pattern (Figure 17) uses lis:DoubleMeasureTypeDatum as the datum class for real-valued measurements. It is flagged with ? in the diagram, indicating that the exact IDO datum class to use for this purpose has not been confirmed. Clarification is needed from the IDO core team. |
| OI-03 | Single vs. dual OWL parent for CFIHOS tag / equipment classes | For each CFIHOS equipment class, two OWL classes are defined (-T tag class and -E equipment class). The question of whether both should inherit from a single IDO parent class, or from two separate IDO parents (one in the specified-plant layer, one in the actual-asset layer), remains open (see Tag and equipment class distinction). |
| OI-04 | cfihos:hasAssigned and cfihos:hasDatum property status |
The object properties cfihos:hasAssigned and cfihos:hasDatum are used in the CFIHOS Semantics patterns for assigned (non-quantifiable) properties. Their formal relationship to lis:hasQuality and lis:qualityQuantifiedAs in IDO core has not been established. |
| OI-05 | CFIHOS placeholder URIs | Placeholder URIs of the form cfihos:CFIHOS-xxxx1 are used in worked examples pending the publication of stable CFIHOS RDL IRIs. These must be replaced with the URIs from the official CFIHOS RDL SPARQL endpoint once available. |
| OI-06 | cfihos:isFulFilledBy vs. lis:implementedBy |
The CFIHOS relation cfihos:isFulFilledBy (linking a tag individual to an equipment individual) covers similar ground to lis:implementedBy (linking a specified entity to a realized asset). Whether these should be declared equivalent (owl:equivalentProperty) or whether one should be declared a subproperty of the other must be agreed between the CFIHOS Semantics Group and the IDO core team. |
| OI-07 | IDO PLM modules incomplete | The IDO PLM modules for Process and Equipment are incomplete and not actively maintained (see Alignment with DEXPI). The DEXPI alignment work used ISO 15926 Part 4 as reference data library and QUDT for units as a workaround. A roadmap for completing or replacing the PLM modules is needed. |
| OI-08 | lis:ActivityProfile for process-part properties |
The modeling of physical-quantity properties associated with process activities (e.g. DifferentialPressure of Pumping UO002) must be compiled with the lis:ActivityProfile concept of IDO. The correct pattern for this combination is still open and must be resolved with the IDO team. |
| OI-09 | lis:hasQualityQuantifiedAs / lis:quantifiesQuality for identification properties |
The identification property pattern (see Pump Lifecycle Use Case, §5.3.2) reuses lis:hasQualityQuantifiedAs and lis:quantifiesQuality to connect an Identifier quality to its datum. Whether these properties are intended for identification (as opposed to quantification) must be clarified with the IDO team. |
| OI-10 | lis-ext:specifiesTechnical requires IDO team agreement |
The object property lis-ext:specifiesTechnical (with inverse lis-ext:specifiedTechnicalBy) is introduced in the DEXPI alignment layer to relate functional specified objects to physical/technical specified objects within the specified plant world. This concept is not in base IDO and must be agreed by the IDO team before it can be considered stable. |
Appendix A: Alignment with ISO 23726-1 principles¶
At the time this guideline was written, there was only a first draft of ISO 23726-1 Overview and fundamental principles. The official process to develop a new standard was about to start. In order to have a stable basis of fundamental principles for this guideline, this appendix collects an extract of the principles relevant to this guideline.
This appendix organizes the ISO 23726-1 principles thematically and references Clause 6 (and named subclauses where applicable). It explains how each principle is applied in this guideline to the property and pattern library context. (ISO 23726-1 introduces the series' principles and their role for conformity in Clause 6.)
Consistency and semantic integrity¶
What ISO 23726-1 requires: Artefacts in the OBI series must be developed under a coherent set of principles so that semantics remain consistent across domains and documents (principles are defined as binding criteria in Clause 6; see ISO text on the role of principles).
How this guideline applies it: The property library enforces one consistent decomposition for every property (identifier, definition, quantity kind, unit, value constraints, lifecycle, governance) and aligns typology, CQs and pattern templates to a single semantic backbone to avoid divergence in meaning across property descriptions.
Axiomatisation and formal grounding¶
What ISO 23726-1 requires: Definitions and constraints should be formally expressed so they are logically checkable; rule-based elements beyond OWL must not contradict the IDO upper ontology (Clause 6.10 on rule consistency).
How this guideline applies it: Each pattern specifies its axioms (class restrictions, property characteristics, shapes) and, where rules/templates are used (e.g., SPARQL constructs), this guideline requires evidence that results remain consistent with the upper ontology; rule artefacts are treated as supplementary to OWL reasoning, not a replacement.
Reusability and modularisation¶
What ISO 23726-1 requires: Ontologies should be modular to support reuse in different applications; inclusions/exclusions of a module must be justified and documented (Clause 6.7; annotations per Clause 9.3).
How this guideline applies it: The pattern library is modular by design (property-level patterns, cross-cutting patterns). Each pattern states its scope and reuse intent; module boundaries and rationale are documented in the pattern’s metadata and annotation set.
Interoperability and alignment¶
What ISO 23726-1 requires: Alignments with external sources shall be documented using the standard annotation properties (Clauses 8—9). Conflicts between external ontological commitments and existing OBI modeling restrictions must be handled explicitly (Lead-in note before clause 6.7; and clause 6.8 on conflicts).
How this guideline applies it: For every externally aligned property/pattern, this guideline requires explicit alignment annotations (mapping type, provenance, confidence) and keeps the alignment material separate from the core definition so that interoperability is auditable and non-intrusive.
Conflict management¶
What ISO 23726-1 requires: External ontological commitments must not conflict with modeling restrictions in existing OBI ontologies; where conflicts exist, mappings and resolutions shall be proposed and documented as described in the standard (Clause 6.8).
How this guideline applies it: The library records conflict cases (e.g., class disjointness, polysemy) and their resolution pattern (refactoring, reification, bridging). Resolutions and justifications are kept alongside the pattern using the mandated annotation properties.
Traceability and annotation discipline¶
What ISO 23726-1 requires: Proper use of annotation properties is part of quality assurance; missing annotations are treated as evaluation findings (Clause 6.9 mentions missing annotation properties as model-checker issues; alignment documentation shall use specific annotations).
How this guideline applies it: Every pattern/property includes provenance, source, approval state, and lifecycle metadata; the library’s CQ checks include the presence and correctness of required annotations (definition, scope, source, alignment, example).
Evaluation and quality assurance¶
What ISO 23726-1 requires: Ontologies in the series shall have quality tests (reasoners, syntax/model checks) and be reviewed/approved by the appropriate Maintenance Agency; typical issues include polysemy, unintended synonyms, and missing annotations (Clause 6.9).
How this guideline applies it: The library mandates CQ gates for patterns (linting, reasoning, test cases). Findings such as homonyms/synonyms are recorded with corrective actions before publication.
Rule consistency¶
What ISO 23726-1 requires: Rules in non-OWL languages must yield results consistent with the upper ontology; such rules complement but do not replace OWL consistency checking (Clause 6.10).
How this guideline applies it: Any transformation/generation rules packaged with a pattern (e.g., constraints, template fills) include conformity evidence and test fixtures; the pattern may only ship with rules that demonstrably preserve the intended semantics.
Governance and ownership¶
What ISO 23726-1 requires: Shared artefacts managed within the ISO OBI community are under an ISO-recognised Maintenance Agency; artefacts by external groups require independent evaluation of their alignment against the Clause 6 principles (Clause 6.11).
How this guideline applies it: Patterns have clear ownership, release/versioning, and change control. External contributions undergo independent review for alignment with these principles before inclusion.
Maintenance agencies and process¶
What ISO 23726-1 requires: ISO-recognised and ISO-external Maintenance Agencies manage updates/publication and ensure a documented, auditable quality process; regular maintenance cycles are prescribed by ISO (Clause 6.12).
How this guideline applies it: The library defines release cadences, namespaces, publication endpoints, and an auditable workflow (proposal → review → acceptance → publication), aligned with the roles and responsibilities of Maintenance Agencies.
References¶
-
IEC 61360-1:2017 — Standard representation of product properties and their values — Part 1: Principles and methods. International Electrotechnical Commission, 2017.
-
QUDT Ontology — Quantities, Units, Dimensions, and Types. https://qudt.org/. QUDT.org, 2024.
Revision history¶
| Version | Date | Contributor | Contributions |
|---|---|---|---|
0.1 |
2025-08-26 |
Andreas Neumann |
Initial draft |
0.2 |
2025-09-02 |
Andreas Neumann |
0. new sections mainly contributed by Onno Paap, Hint from Magne Valen-Sendstad added; |